
Run LLM Model Locally using Ollama
LLM Models at your fingertips

Diving into Generative AI: From Concepts to Hands-On Implementation
After exploring numerous tutorials on Generative AI, I reached a point where I felt I understood the theoretical distinctions between Generative AI, Deep Learning, and related concepts. However, theory alone wasn’t enough—I felt an itch to move beyond passive learning and get my hands dirty with real-world implementation. The desire to bring these ideas to life pushed me to find a practical starting point.
The Challenge: Running Large Language Models Locally
A couple of years ago, as the AI revolution was gaining momentum, there was a prevailing notion that hosting large language models (LLMs) required high-powered GPUs. The assumption extended to cloud service providers too—only those with specialised hardware could run these computationally intensive models effectively.
But what if we challenge that narrative? With advancements in chip technology, even consumer-grade hardware like a MacBook with an M1 chip and 32GB of RAM holds promise. The question is: can such a setup handle the demands of hosting and running LLMs? Let’s put it to the test.
Enter Ollama: Bringing LLMs to Your Fingertips
What is Ollama?
Ollama is a software platform designed to simplify the use of LLMs. It enables developers and teams to run models efficiently and securely on local machines or within private environments. Essentially, Ollama is an LLM provider that allows users to host multiple models while offering an intuitive and user-friendly experience.
This makes it an ideal solution for those who want to experiment with LLMs without depending on cloud infrastructure or expensive GPUs. Plus, it ensures that data stays local, addressing privacy concerns often associated with cloud-based AI solutions.
Getting Started with Ollama
Setting up Ollama is straightforward. Here’s how to get started:
1. Visit Ollama.com: Head to the official website to download the installer.
2. Choose Your Operating System: Select the version compatible with your machine (macOS, Windows, etc.).
3. Run the Installer: The installation process is smooth and hassle-free.
Once installed, you’ll have access to a suite of tools to start running and managing LLMs locally.
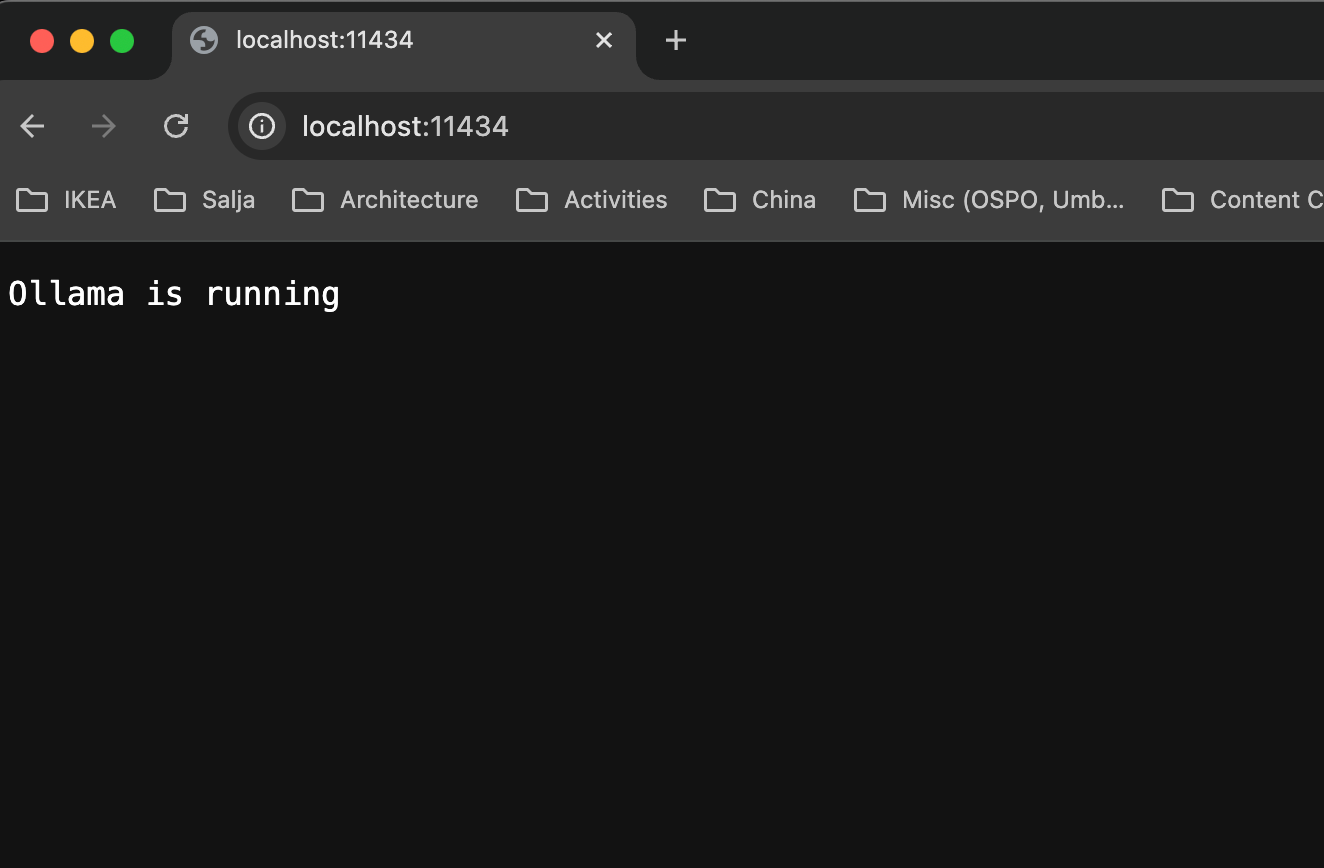
Ensure Ollama Model is running by accessing 11434 in localhost.
Pulling the Latest Models: LLaMA 3.3, Mistral, Phi-4, and More
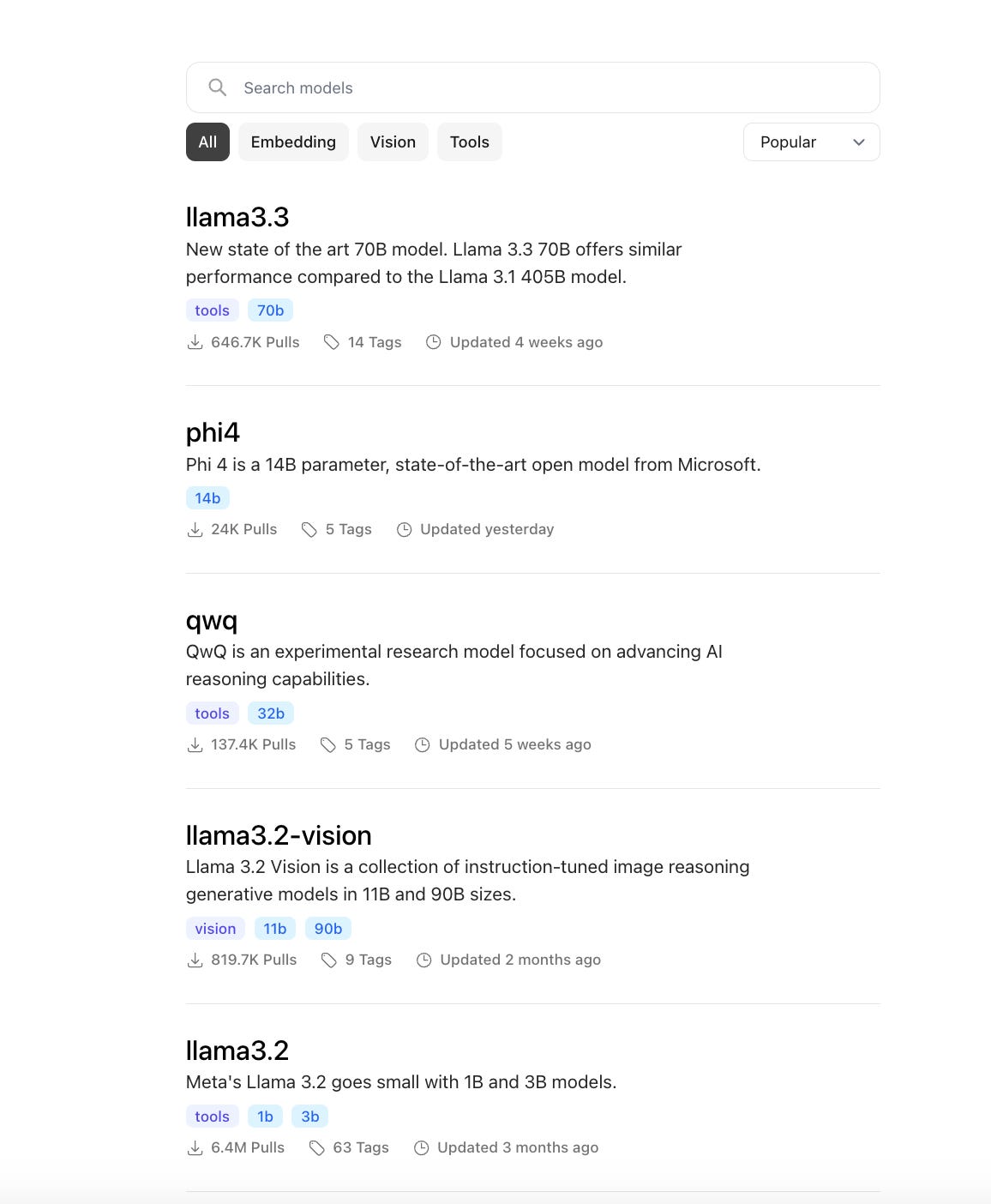
Ollama allows you to pull pre-trained models quickly and efficiently. To download and install models, follow these steps:
1. Open the Terminal: Launch your terminal or command-line interface.
2. Pull a Model: Use the ollama pull command to download the desired model. Examples:
LLaMA 3.3:
ollama pull llama3.3
Phi4:
I had to try Phi4 for this tst. This was launched by Microsoft only a couple of days back.
ollama pull phi4
Verify Installation: After the download completes, use the ollama list command to confirm the models are available locally.
ollama listRunning and Testing a Model
Once a model is downloaded, running it locally is just as straightforward:
Start the Model: Use the following command to start a session with your chosen model:
ollama run llama3.2• Let’s go ahead and ask few questions:
I am using Llama 3.2 Model and Phi4 Model for the comparisons. Let’s see some sample response to our queries.
Phi4 Model
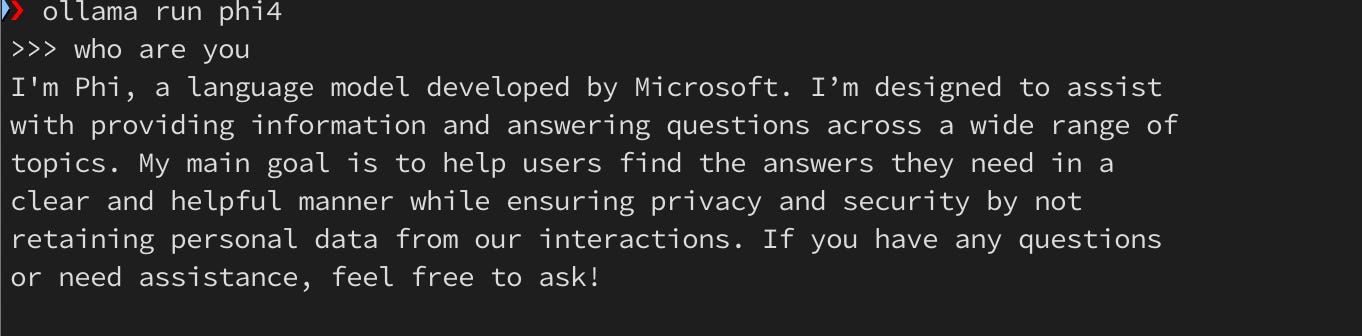
Llama 3.2 Model

Now, I wanted some ideas about the trending songs about 2024. Let’s see how the models fared.
Phi4 Model
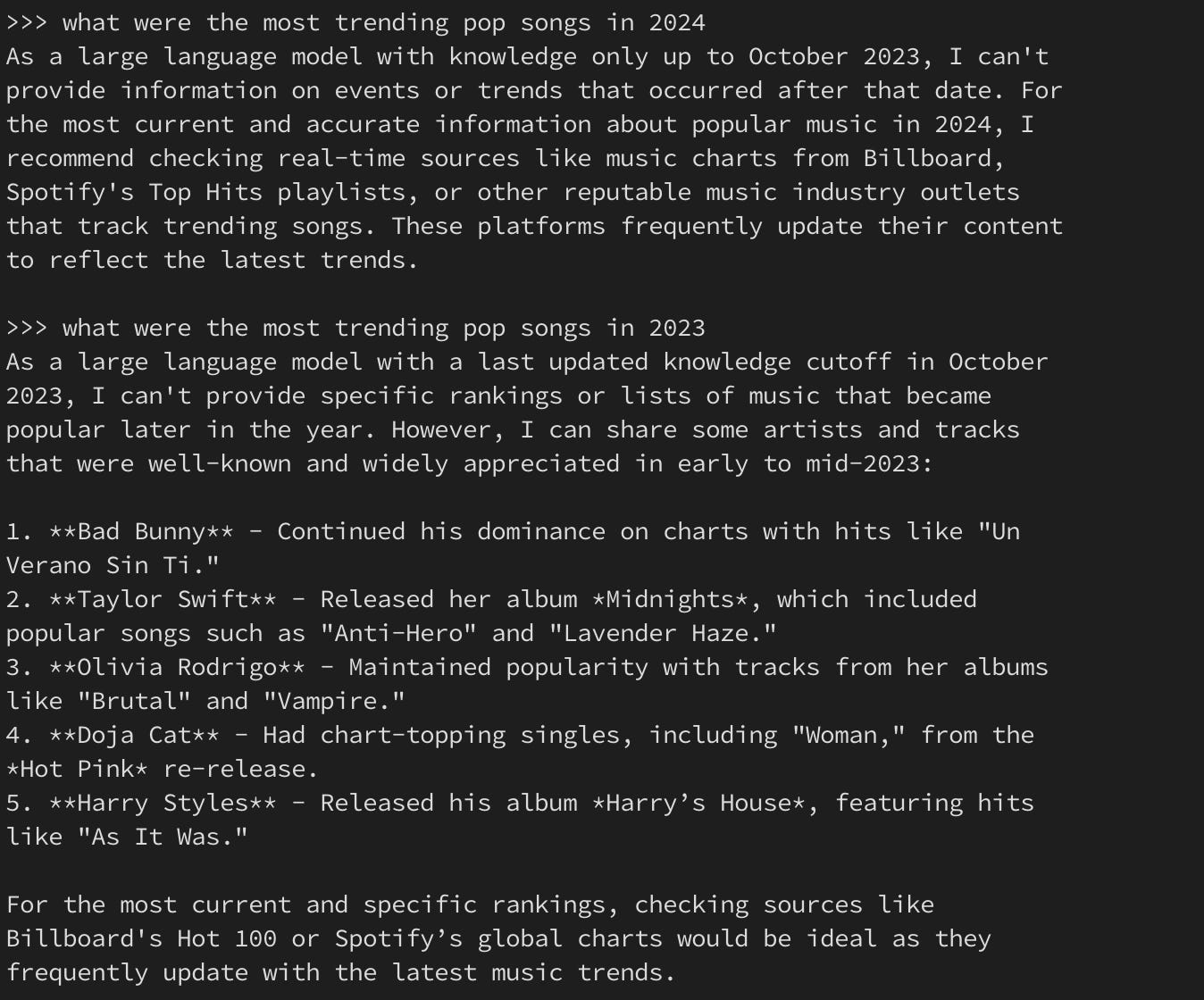
Observation: Phi4 stated that it was not able to provide an answer for 2024 since it was trained with Dec 2023 Dataset and it suggested alternate source for looking up on the information. Ok, that’s fair. I tweaked my prompt and asked for the result set from 2023 instead. Voila, Bad Bunny dominated the chart followed by Taylor Swift.
Llama 3.2 Model
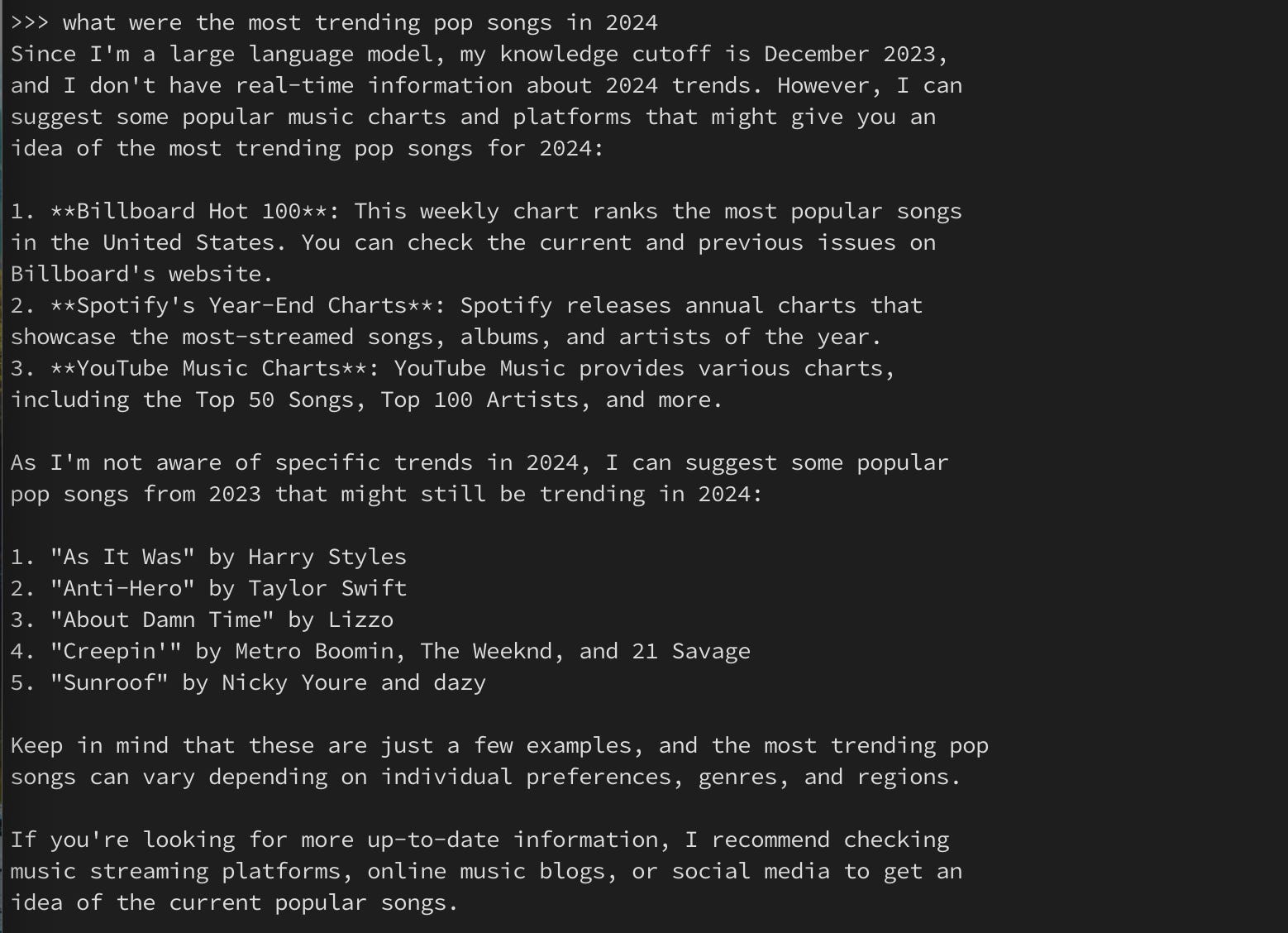
Observation: Same as Phi4. It was also trained on 2023 data and doesn’t have access to 2024 songs. However, as one can see, it already provided a curated list of songs from 2023 without me asking for it. 10 points to Gryffindor Llama.
It’s worth mentioning that I didn’t have to swap the models in Ollama for getting an answer to my query. My Mac was able to handle the request in two separate instances of terminal at the same time.
Rest API
I wanted to this a step further and pass the prompt through a Rest Service. Enter Postman as the Rest Client.
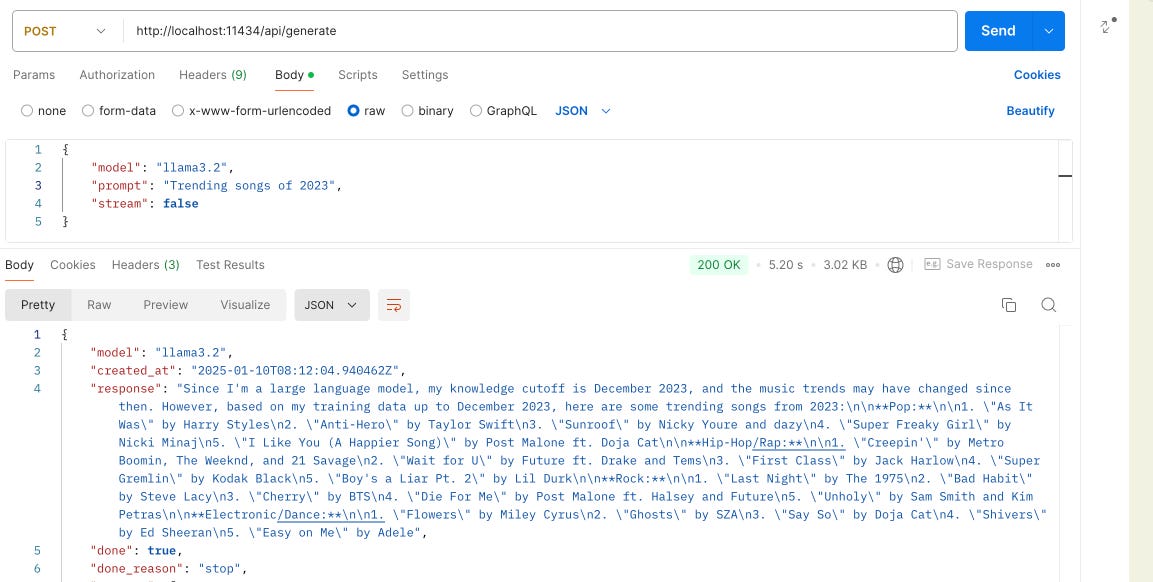
Changing the Model will enable to get the response from the desired Model (either Llama 3.2 or Phi4)
Possible Benefits:
Data Privacy and Security: The data is secure. It’s within our own workstation. No need of passing the information through chat client that will process our sensitive information.
Offline Accessibility: This is a big win for me. No longer we need a dedicated internet connection. We can interact with our LLM Models even without connectivity.
Cost Saving: No longer we are dependent on costlier subscription model. We can use the free open source LLM Models and get the same response as we desire.
Multiple Models: There are models who are efficient in some particular tasks and some are efficient in others. We can swap the models as per our liking without any hassle.
Reduce Dependency on Cloud Services.
Lower Latency since everything is hosted locally.
Conclusion: Generative AI at Your Fingertips
For anyone eager to move from theoretical learning to practical exploration of Generative AI, Ollama is a fantastic starting point. It bridges the gap between the need for high-powered infrastructure and the accessibility of consumer-grade hardware like the MacBook M1.
Why not take the leap and explore the potential of Generative AI with Ollama? Your journey into hands-on AI experimentation is just a few commands away.