
Building an AI Agent with Langflow and RAG
Introduction to AI Agent and RAG

The AI landscape is rapidly evolving, with frameworks like LangChain and Autogen gaining popularity in the industry. Today, we’ll explore how to build an AI Agent using Langflow—a tool that leverages Retrieval-Augmented Generation (RAG).
What is Langflow?
Langflow is a low-code platform designed for developers to effortlessly create robust AI agents and workflows that can integrate with any API, model, or database.
The best part? You don’t need extensive expertise in technologies like Python. Langflow provides pre-built components, letting you focus on assembling your logic to achieve the desired outcome.
Intrigued? Let’s Dive In.
The Problem with LLMs
Large Language Models (LLMs) are trained on specific datasets, limited to the knowledge available at the time of training. This means they may struggle to answer queries about recent events or require web scraping to gather the latest information.
How can we address this limitation? There are two main approaches:
1. Fine-tuning the LLM with additional data.
2. Enhancing the LLM with Retrieval-Augmented Generation (RAG).
We’ll focus on the latter using Langflow.
Langflow Installation
While Langflow has a web version, hosting it locally ensures access to the latest features. Here’s how to set it up:
Install Langflow:
python -m pip install langflowUpdate Langflow to the Latest Version
python -m pip install langflow -URun Langflow
python -m langflow run
Access Langflow locally and you’re ready to start!
Flow 1: Basic Prompting
We will start with Basic Prompting.
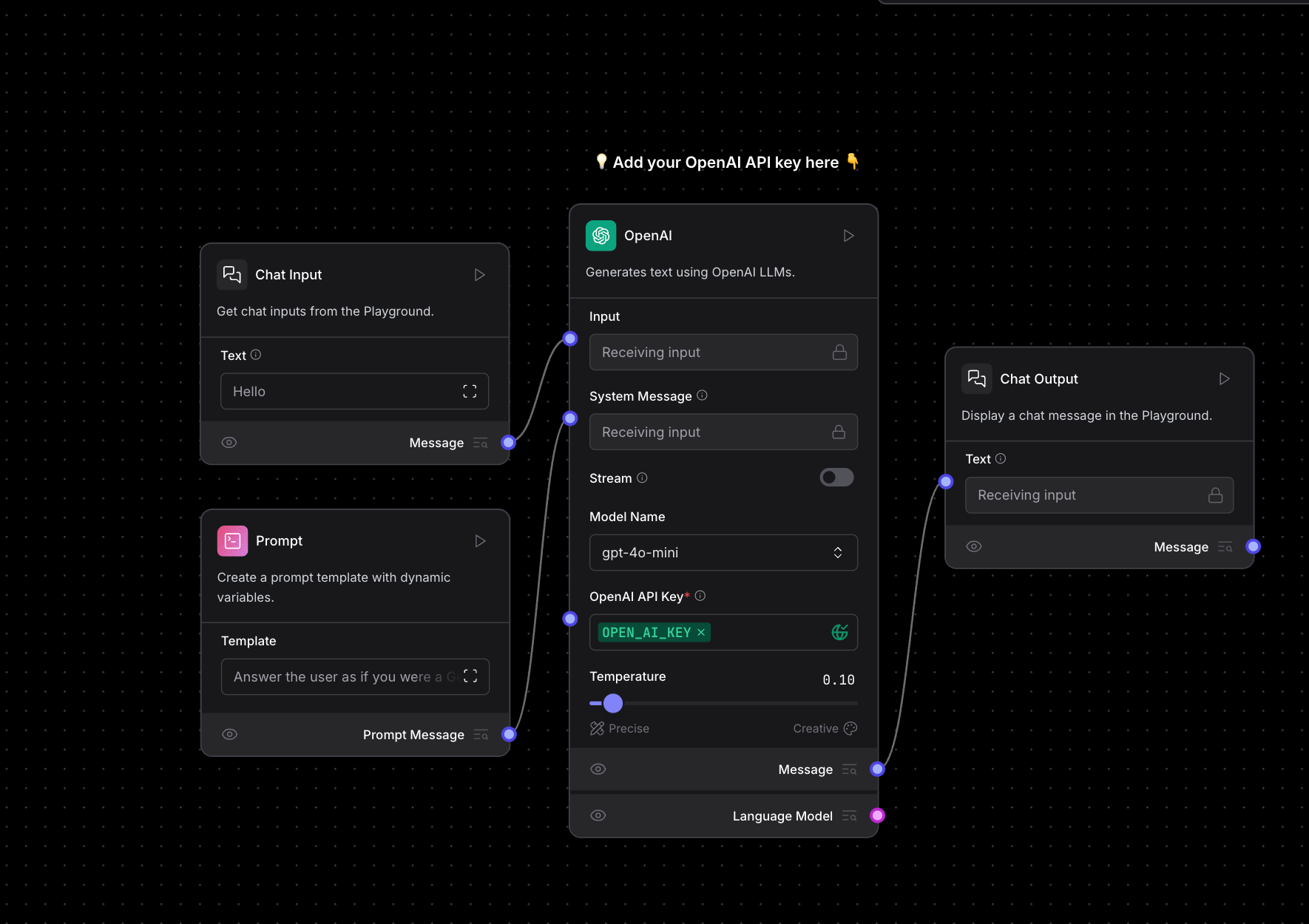
Begin by providing your OpenAI API key.
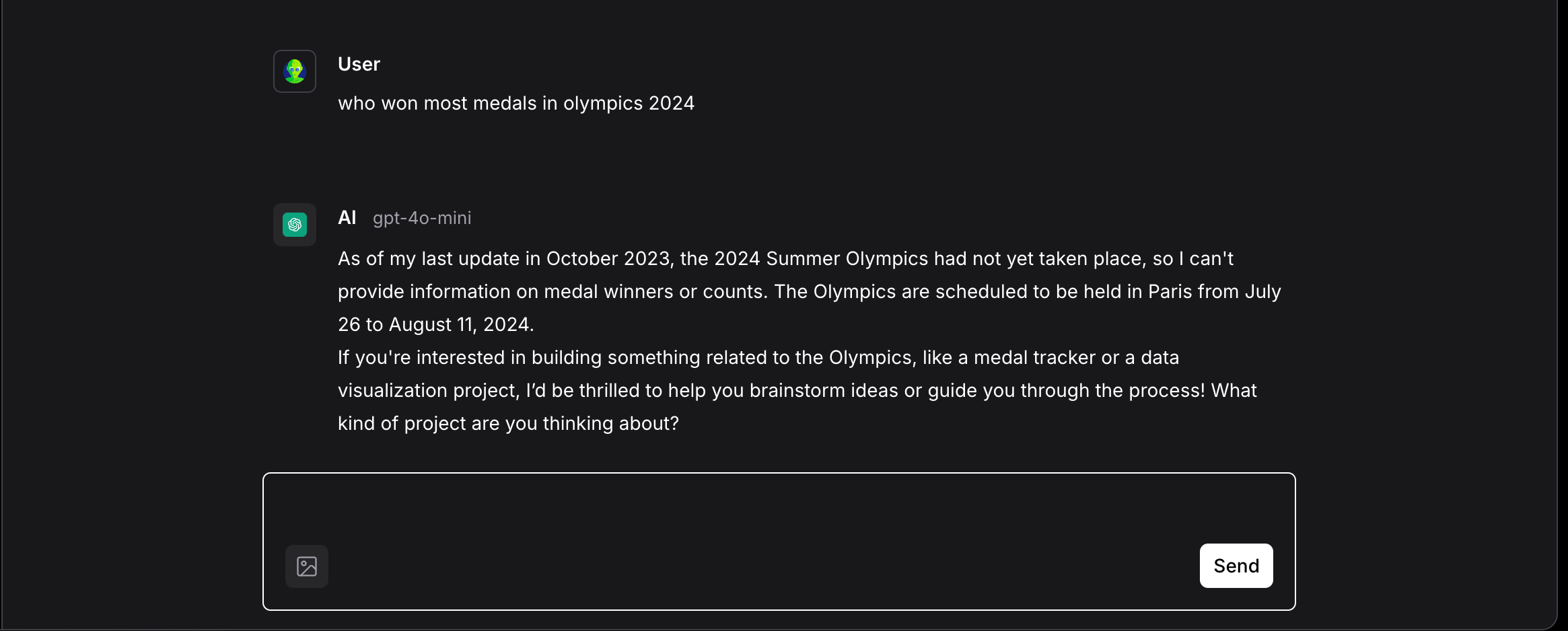
Head to the Playground and test the model. For instance, I asked: “Who won the most medals in the 2024 Olympics?”
The LLM couldn’t respond accurately because its training data is confined to 2023. This demonstrates the need for augmentation.
Flow 2: Creating a Vector Store RAG
Let’s build a RAG using Langflow. Start a new flow and select Vector Store RAG.
What is a Vector Store RAG?
A Vector Store RAG uses a vector database to store semantic embeddings, enabling efficient similarity searches. Here’s how it works:
1. Data Preprocessing: Convert content (e.g., text, images) into numerical vectors using an embedding model (like OpenAI embeddings).
2. Storage: Store these vectors along with metadata in a vector database (e.g., Astra, ChromeDB, FAISS).
3. Indexing: Organise the vectors for quick retrieval of contextually relevant data.
This structure allows the system to retrieve contextually similar information based on the query’s meaning rather than exact keyword matches.
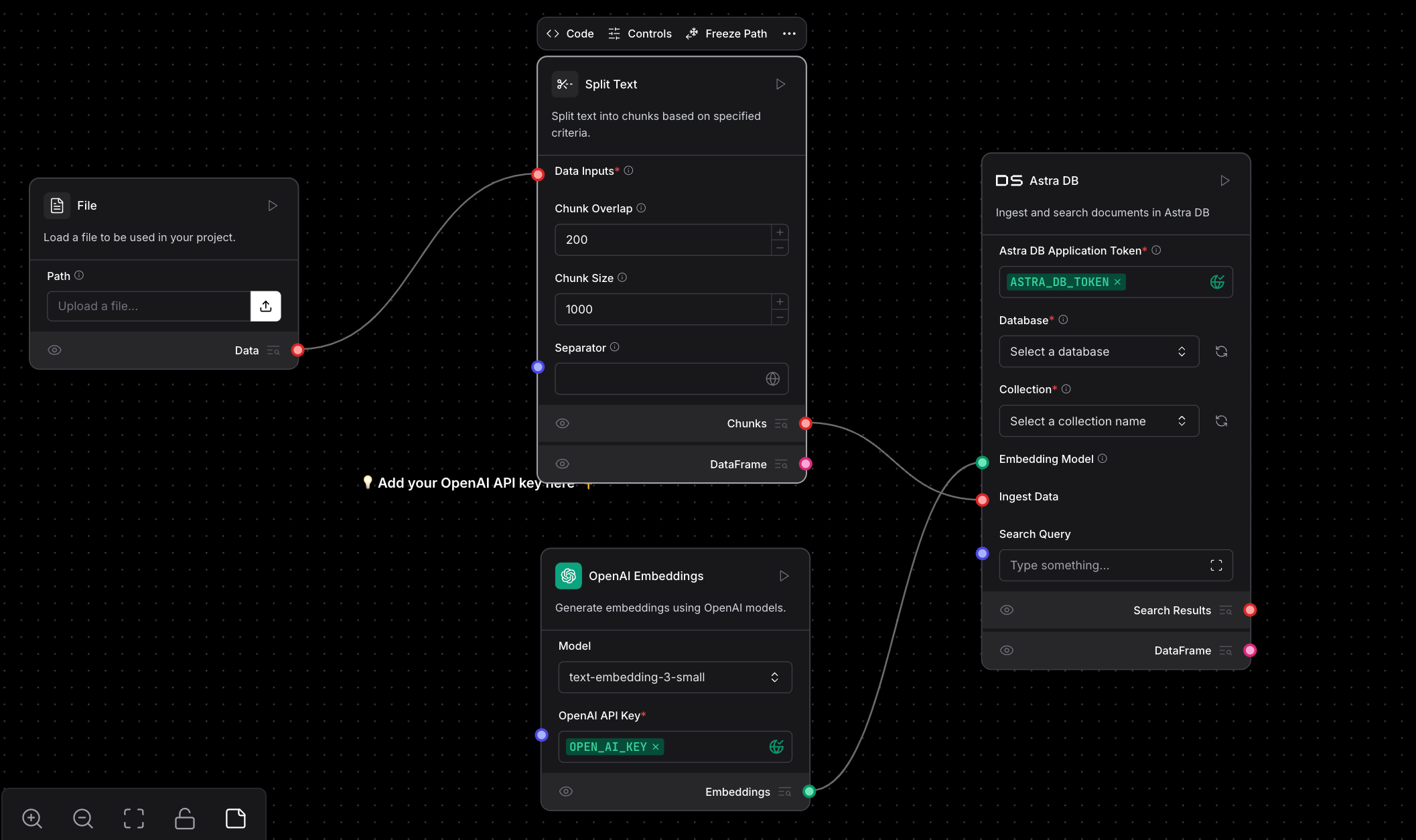
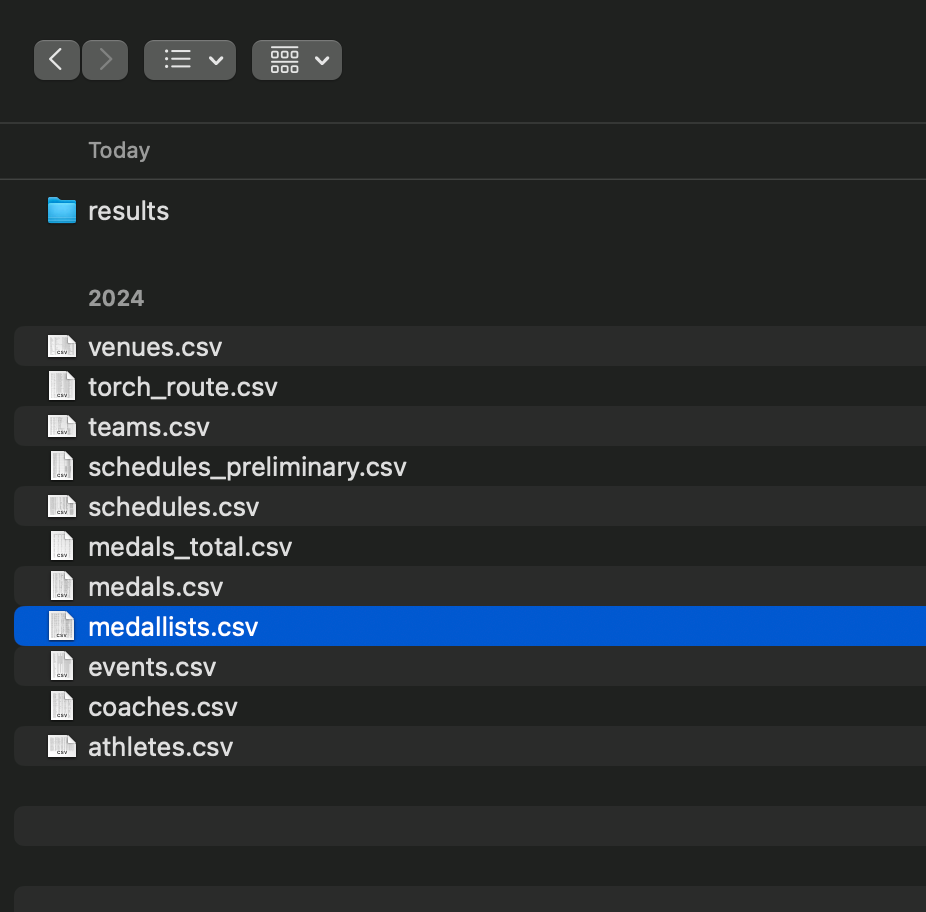
I uploaded a CSV file containing medalist information from the 2024 Paris Olympics.
Selected Astra DB as the vector database. Other options include ChromaDB.
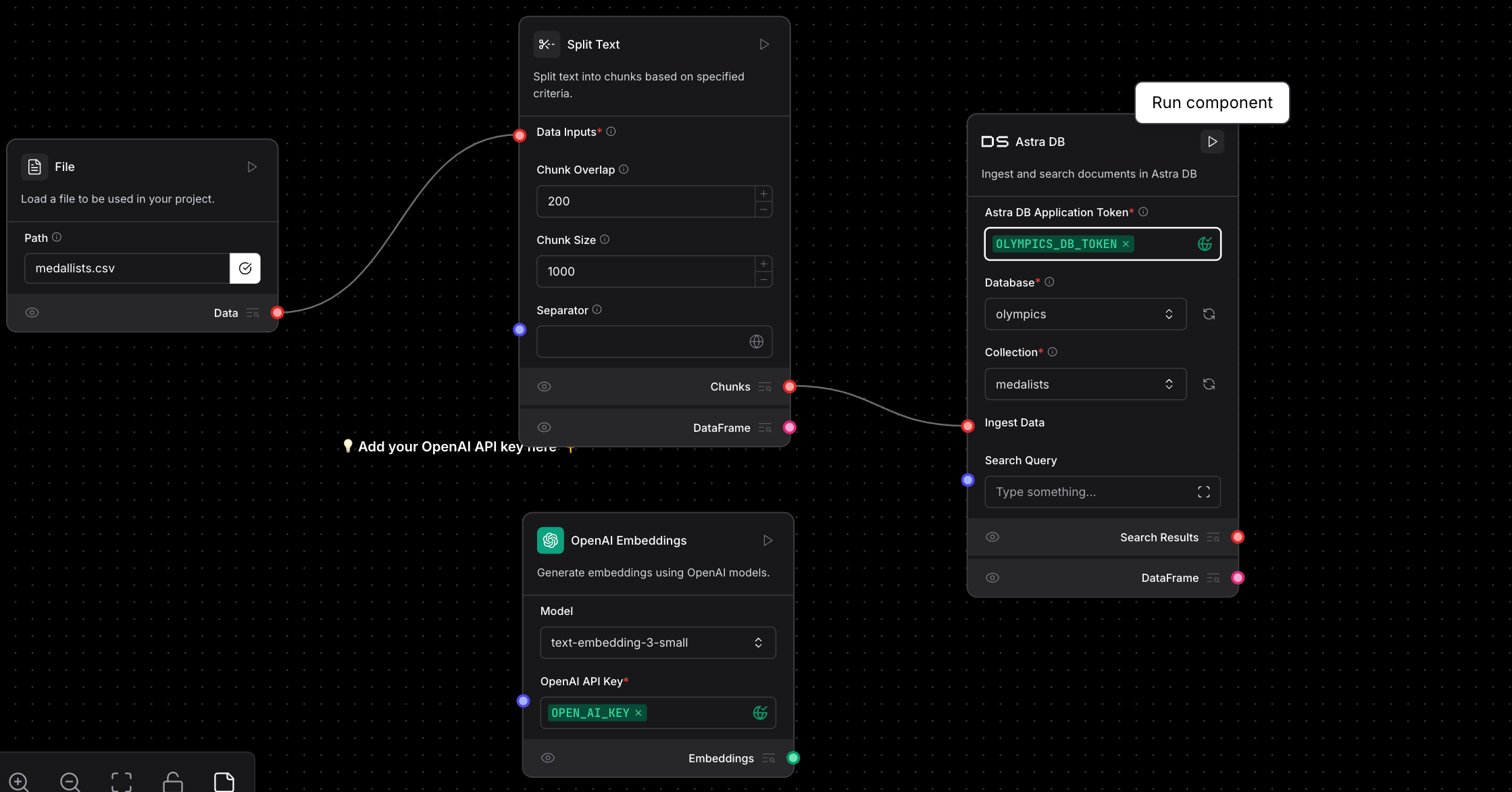
Once we’ve provided the OpenAI and AstraDB tokens, the flow should look like this. Let’s walk through the process of obtaining an AstraDB token, including creating a sample database and collection to store the data.
Let’s open AstraDB in a web page.
Let’s create a New Database. I have named the database as “olympics“.
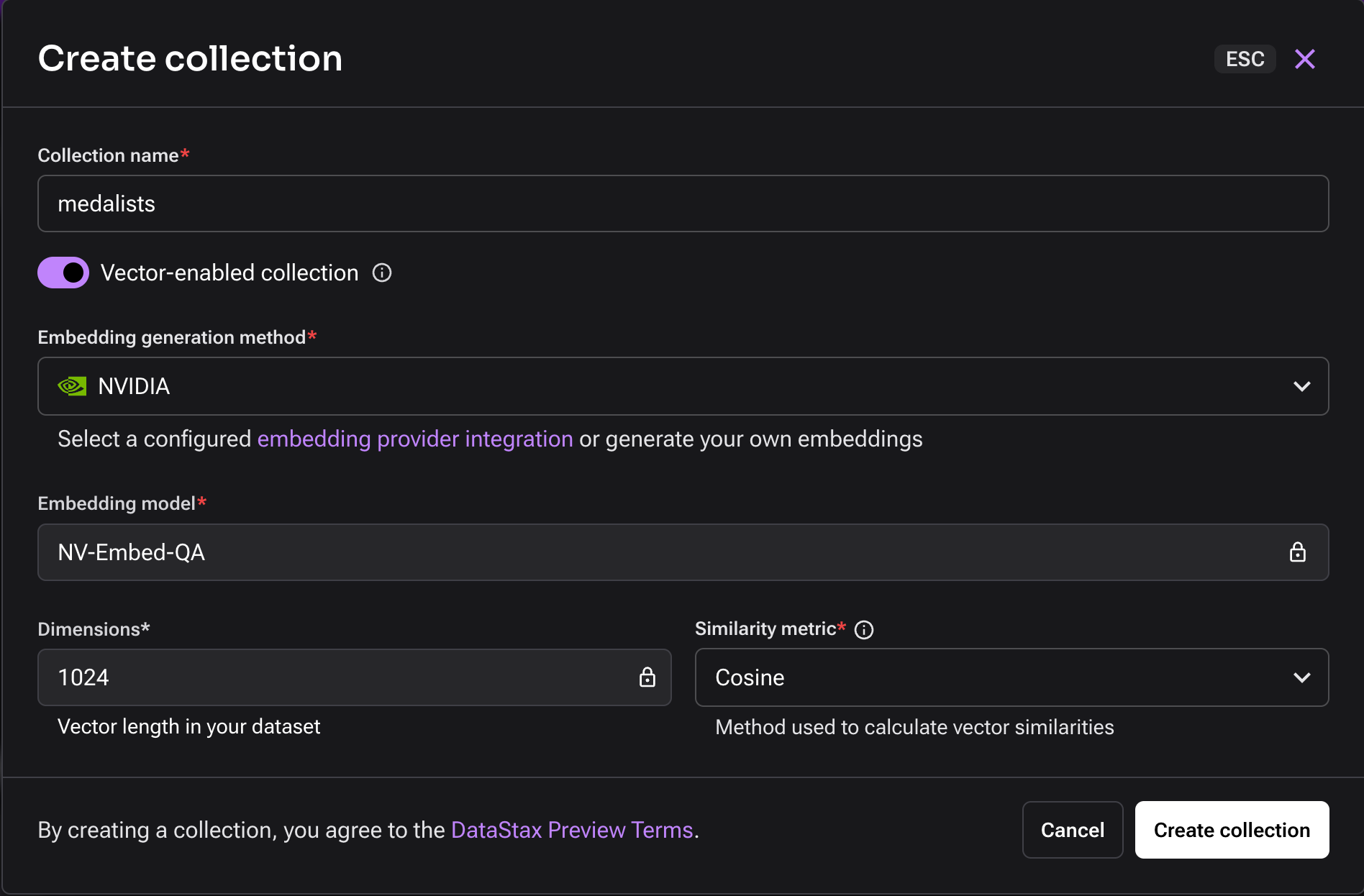
Now, let’s create a collection. As mentioned earlier, we need to choose an embedding model. I’ve selected “NV-Embed-QA” as the embedding generation model. You can choose the dimensions based on your preference; for my dataset, 1024 worked well.
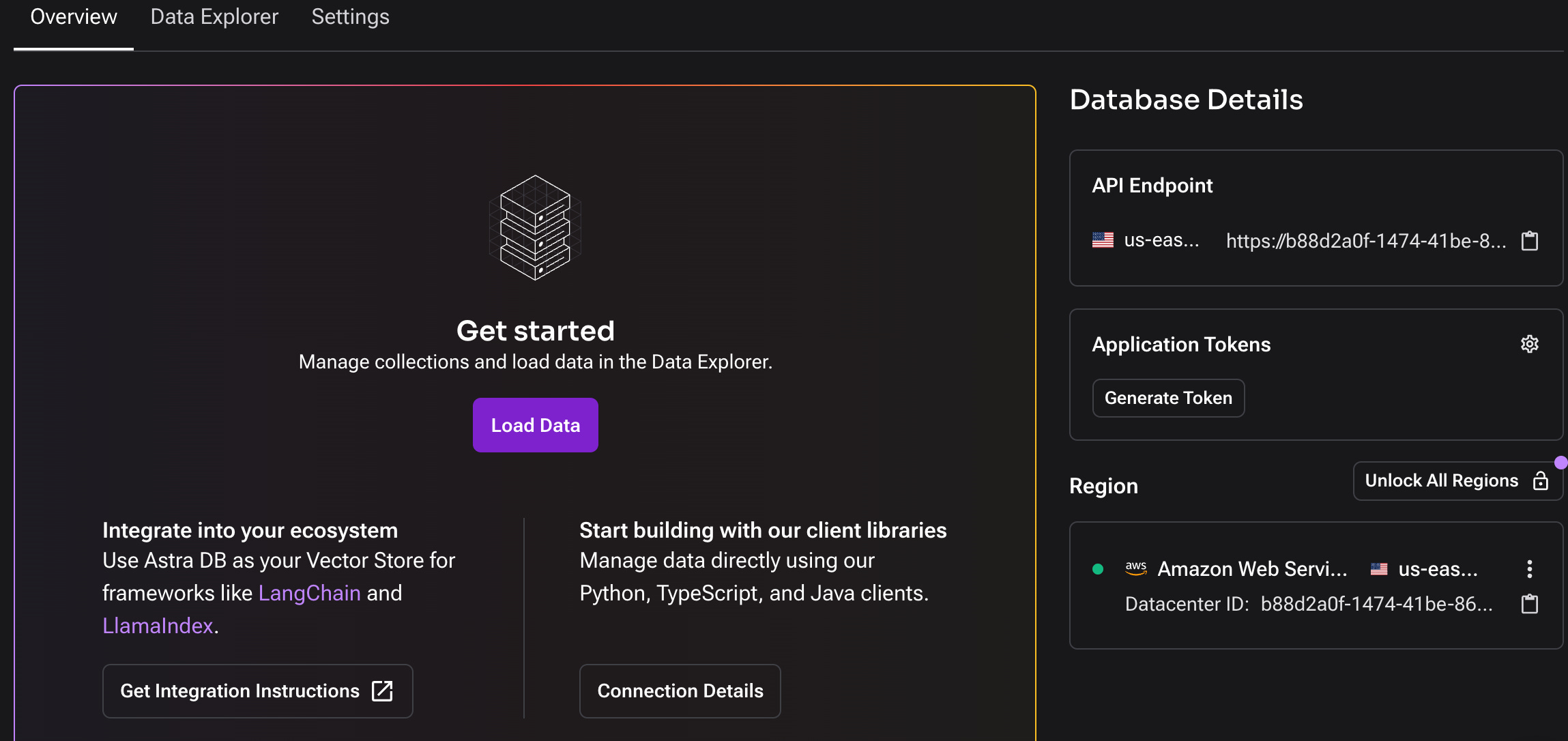
Next, we can obtain the API endpoint here. I’ve chosen AWS as the cloud service provider and US East as the zone.
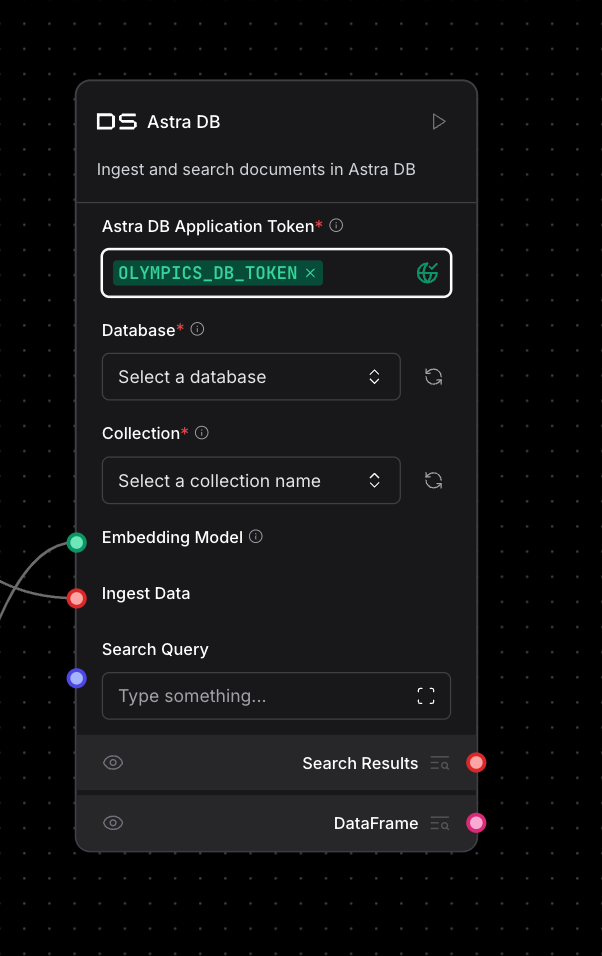
You can generate the Application Token from this location and enter it into Langflow’s Astra DB component. Then, create a global variable called Olympics_DB_Token and assign the token value to it.
Execute the Run Component within Langflow. This should populate the vectors within the database.
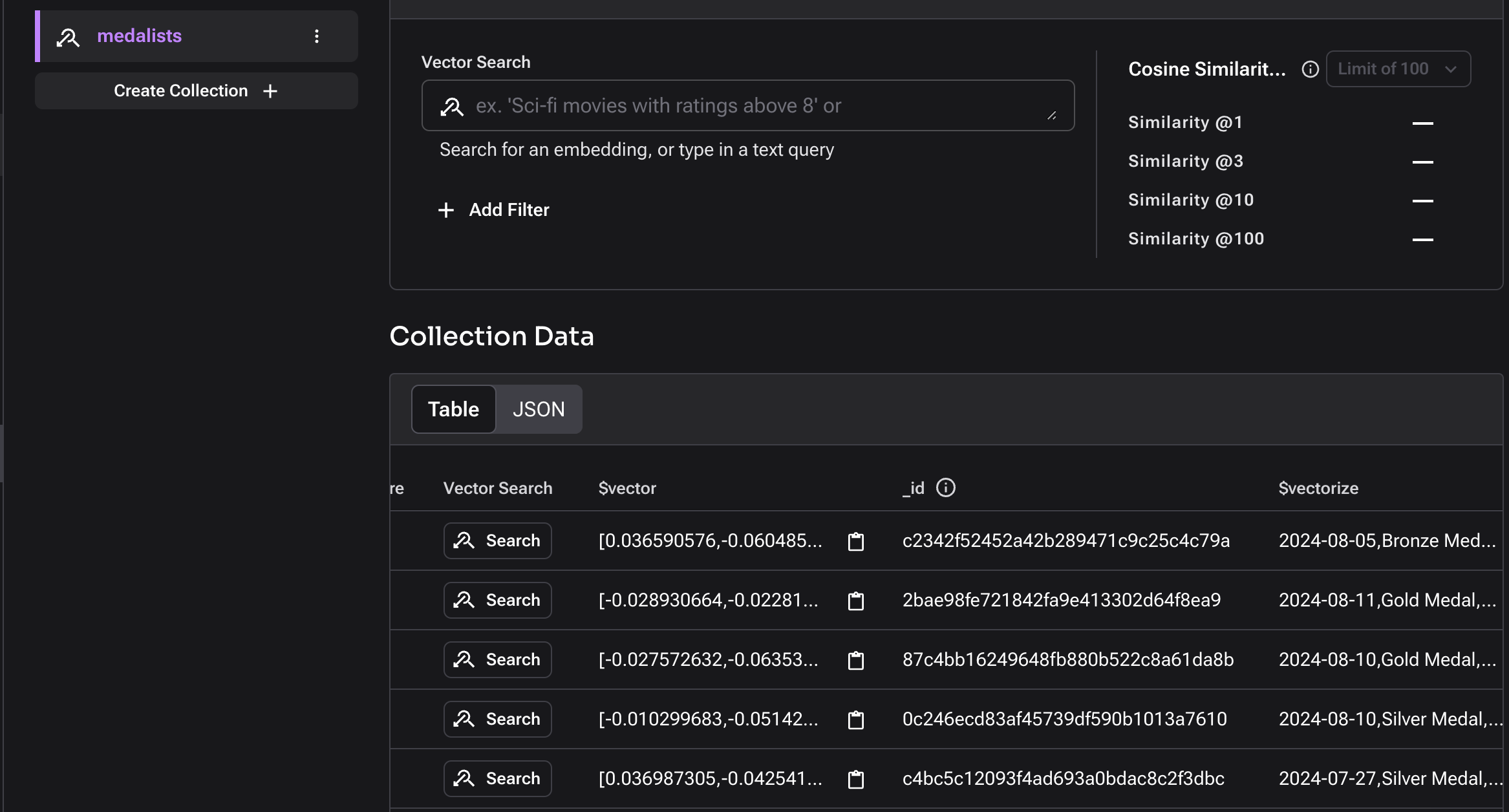
Let’s go to AstraDB page and visualise the data to ensure data has been loaded successfully as shown below.
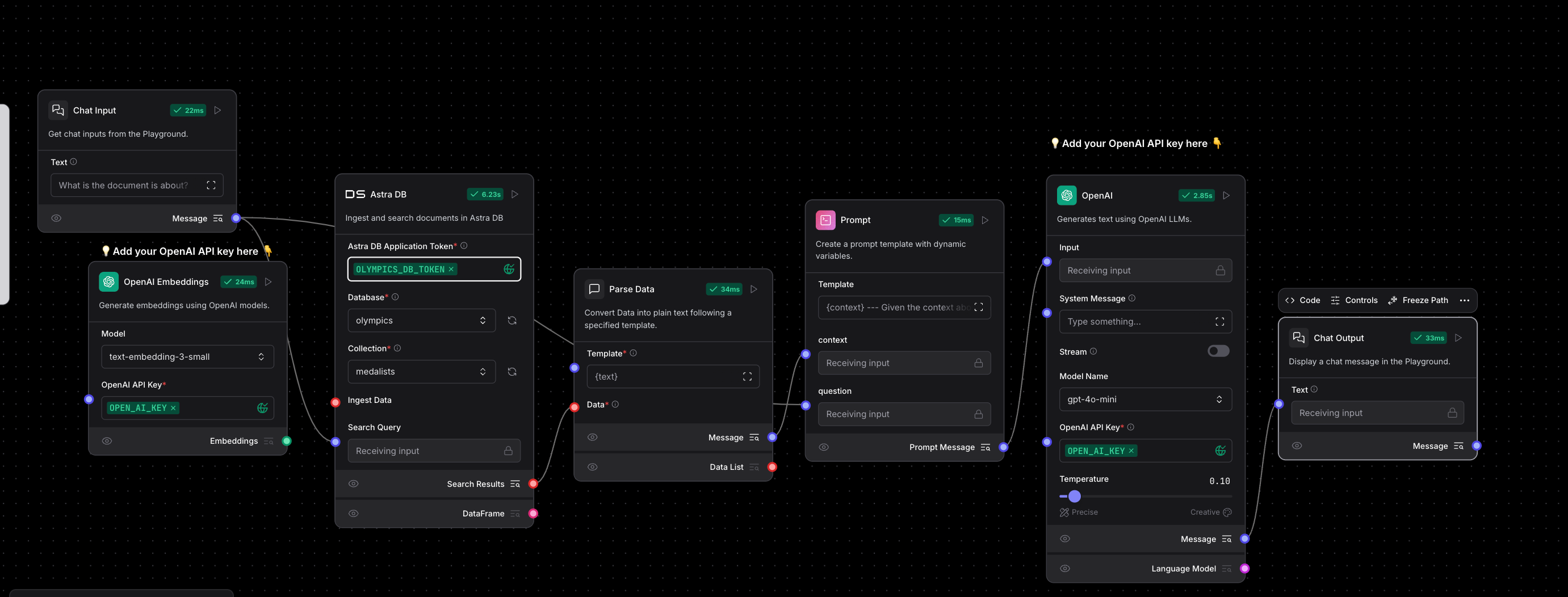
Provide the Same Token Information for Astra DB and Open AI and head over to Playground.
Here, our flow will provide the output based on the RAG Model and make use of parsing the data retrieved from the model and decorate it using the prompt and the data that is passed to the OpenAI Model.
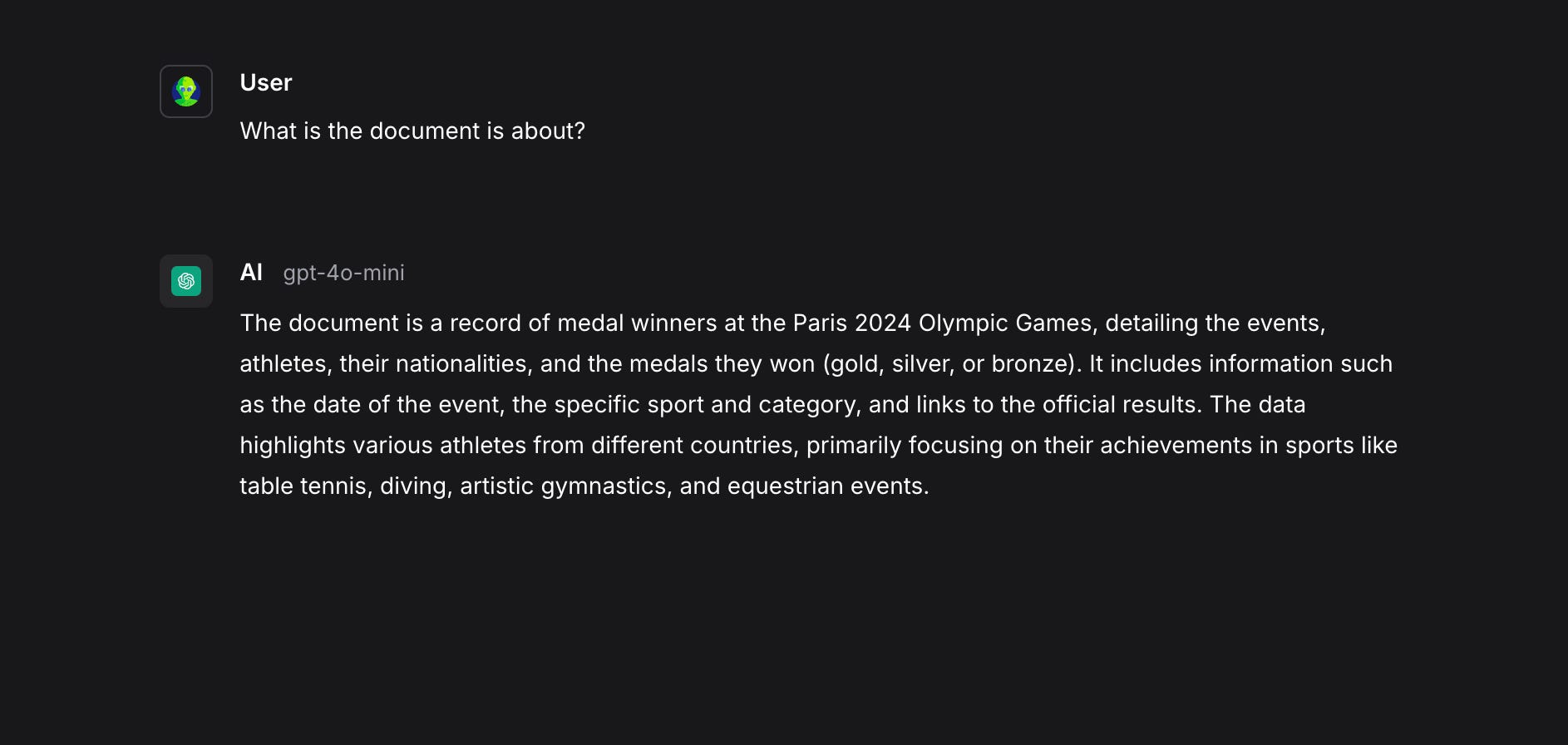
This is what a sample Chat Input and response from the LLM Model looks like based on the content of the RAG.
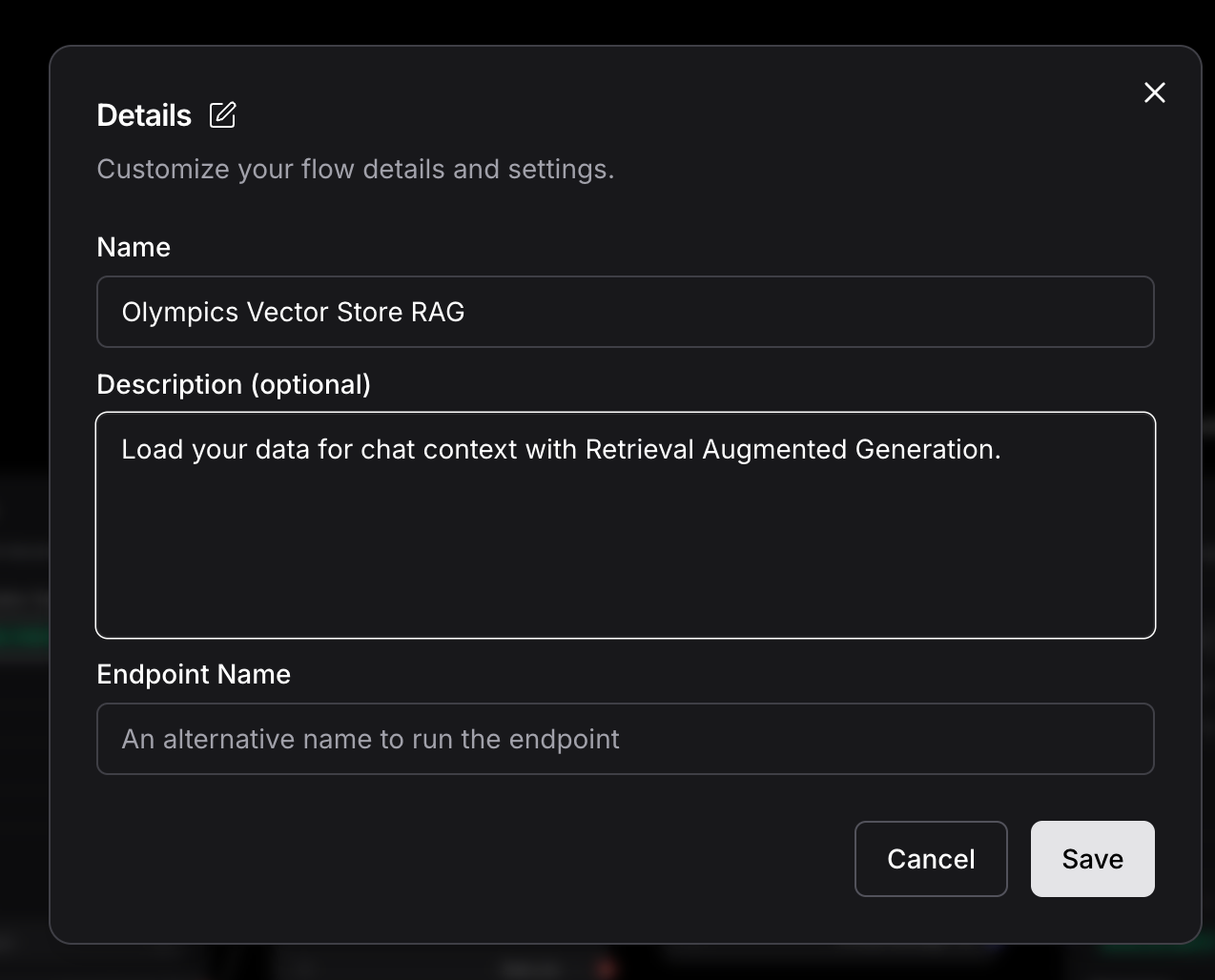
Let’s edit the details for the current flow and give a proper name for the Flow we have just created.
Quite Satisfactory? Yes. Are we done with the topic? Absolutely not.
Flow 3:
Now that our RAG model is functional, let’s empower it with decision-making capabilities using AI Agents.
What is an AI Agent?
An AI Agent leverages multiple tools to handle diverse queries intelligently. For instance:
• A Calculator for math problems.
• A Fetch URL tool for web scraping.
• A RAG Vector Store for domain-specific data retrieval.
Let’s head back to Langflow and click on Create Simple AI Agent. The below template pops up.
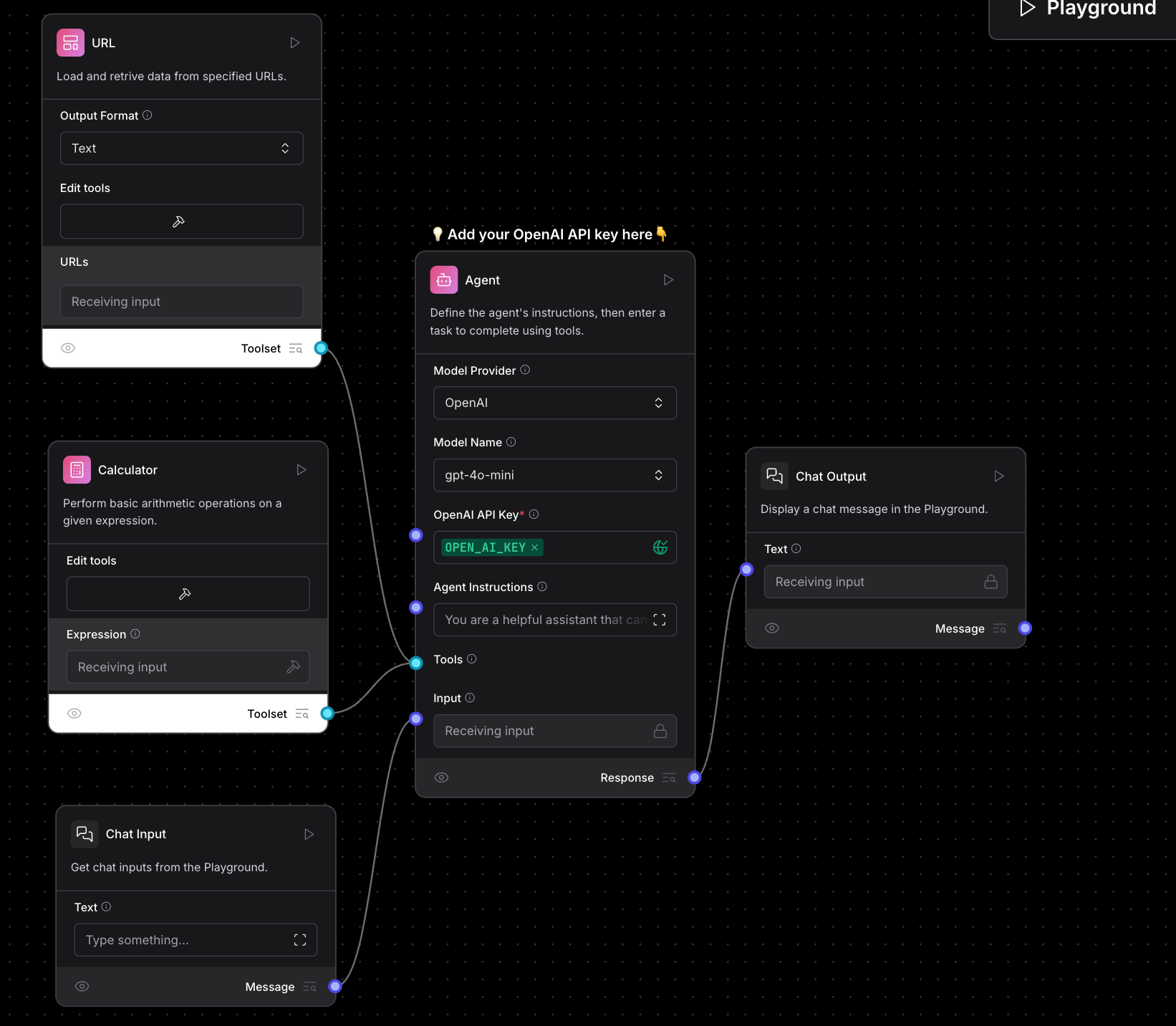
The AI Agent component includes multiple tools, such as a URL fetcher and a calculator. When a user submits a query through the Chat Input, the AI Agent selects the appropriate tool to generate a response.
Let’s test this in the Playground.
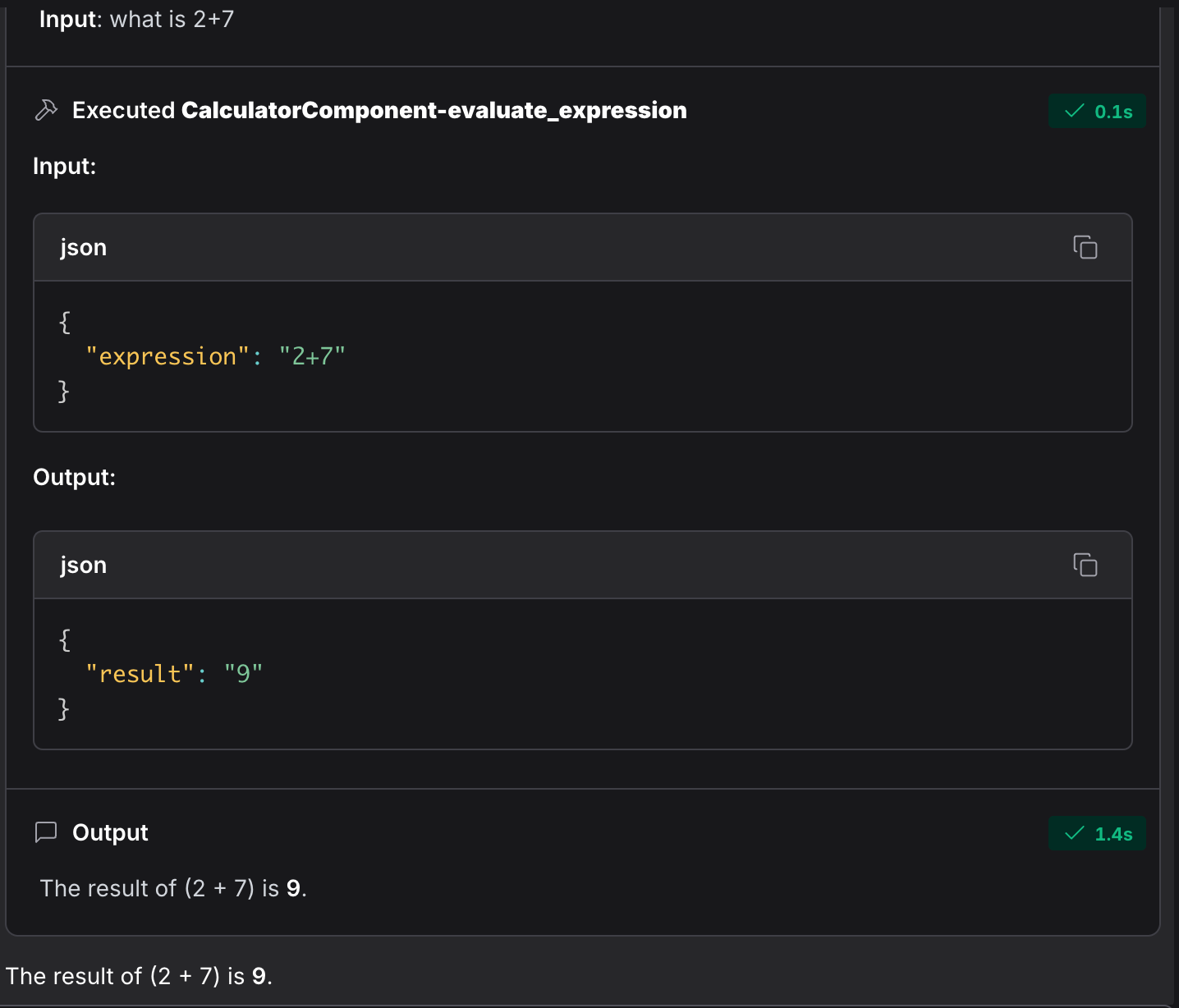
I entered a simple query: “What’s 2 + 7?” The Agent used the Calculator component to provide the correct answer. Simple and effective!
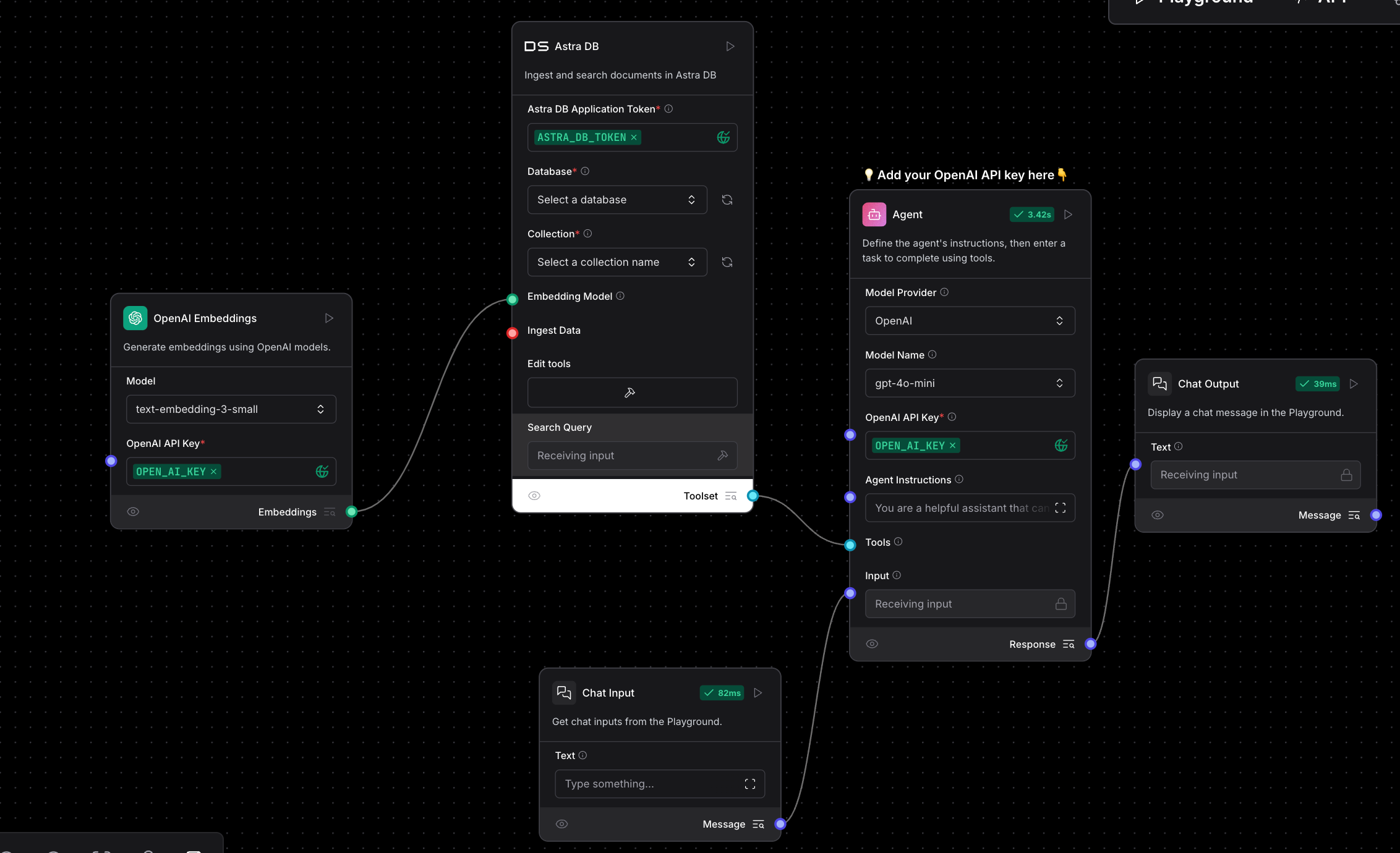
I don’t need the Calculator or Fetch URL components, so let’s remove them. Instead, I want my AI Agent to work with the RAG Vector Database. To achieve this, I’ll add the Astra DB component and configure OpenAI Embeddings as the embedding model. Additionally, I’ll set the component to function as a Tool.
By now, you’re likely familiar with the process. So, without further ado, let’s head to the Playground.
I posed a query to the LLM, instructing it to use RAG as the primary source of information. Sure enough, it utilised the Astra DB Search Documents component to provide an accurate response.
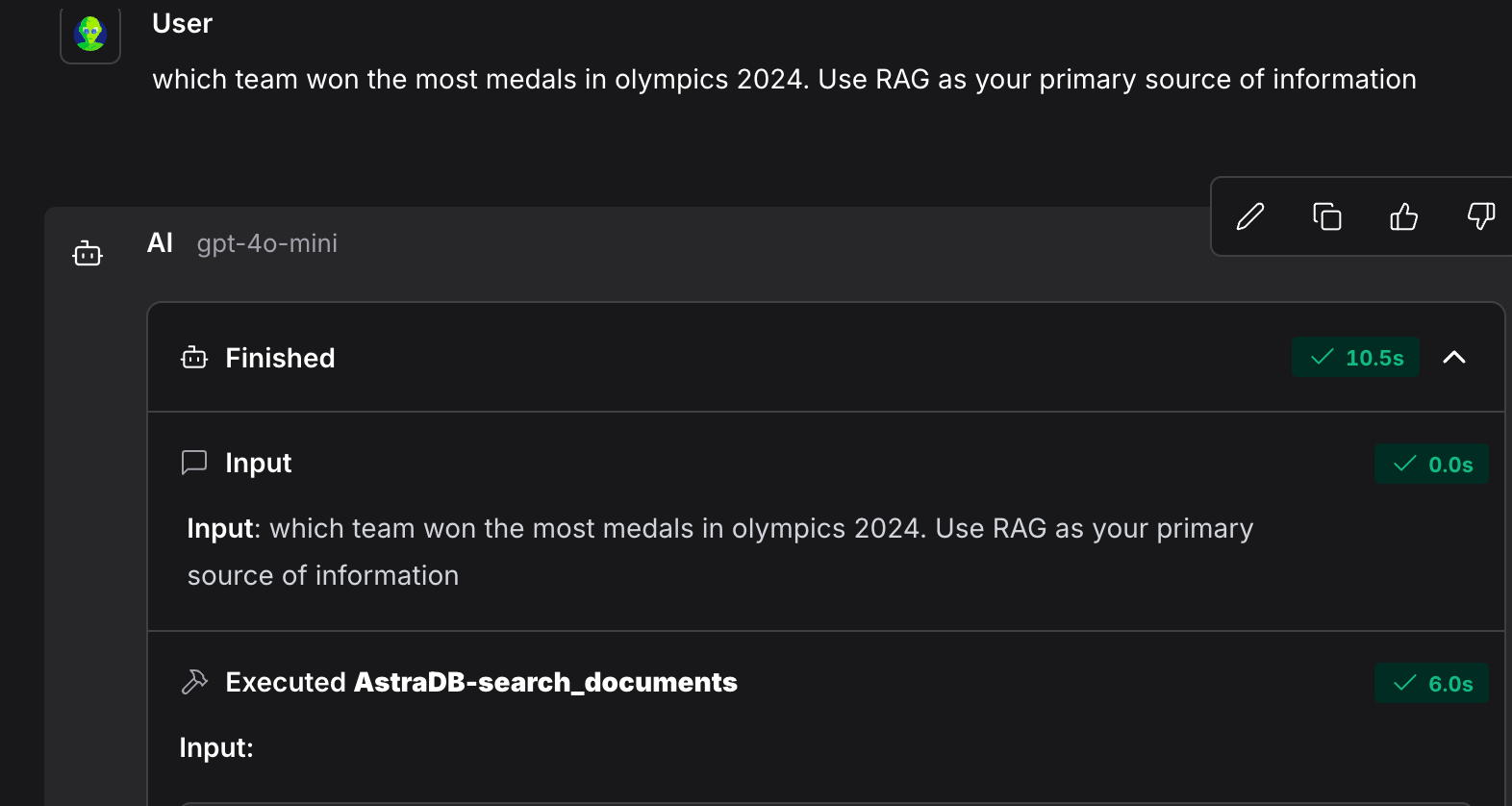

And just like that, our LLM model can now answer queries about the 2024 Olympics—something it couldn’t do before—thanks to RAG. Quite impressive, wouldn’t you agree?
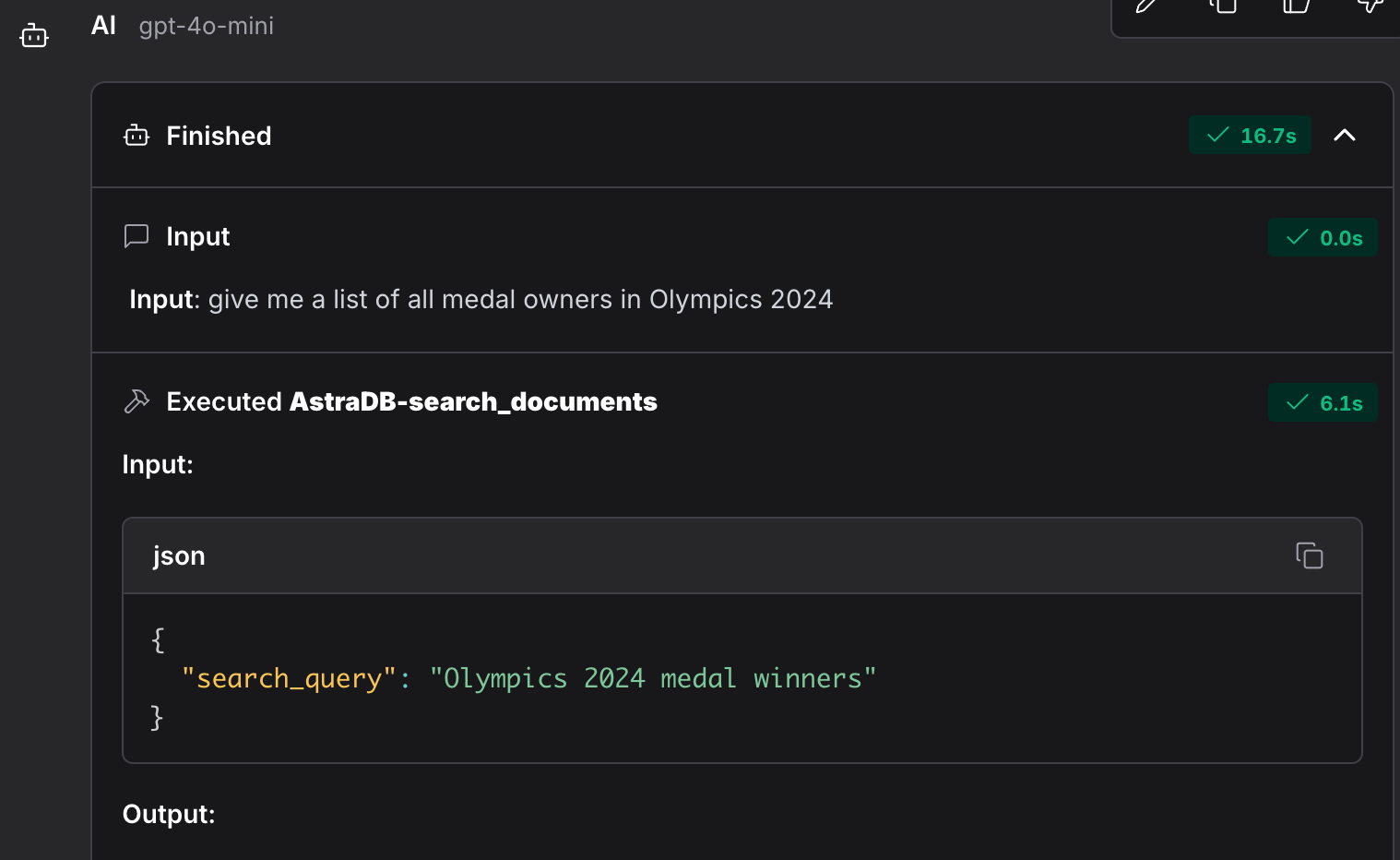

However, its responses are limited to the training set and the RAG model I’ve configured. So, what happens if I ask about something recent that falls outside these categories.
Adding Web Search Capabilities
Enter Tavily AI Search Component which I will plug in as an additional too for the agent to work with.
“Tavily Search API is a search engine optimized for LLMs, optimized for a factual, efficient, and persistent search experience.”
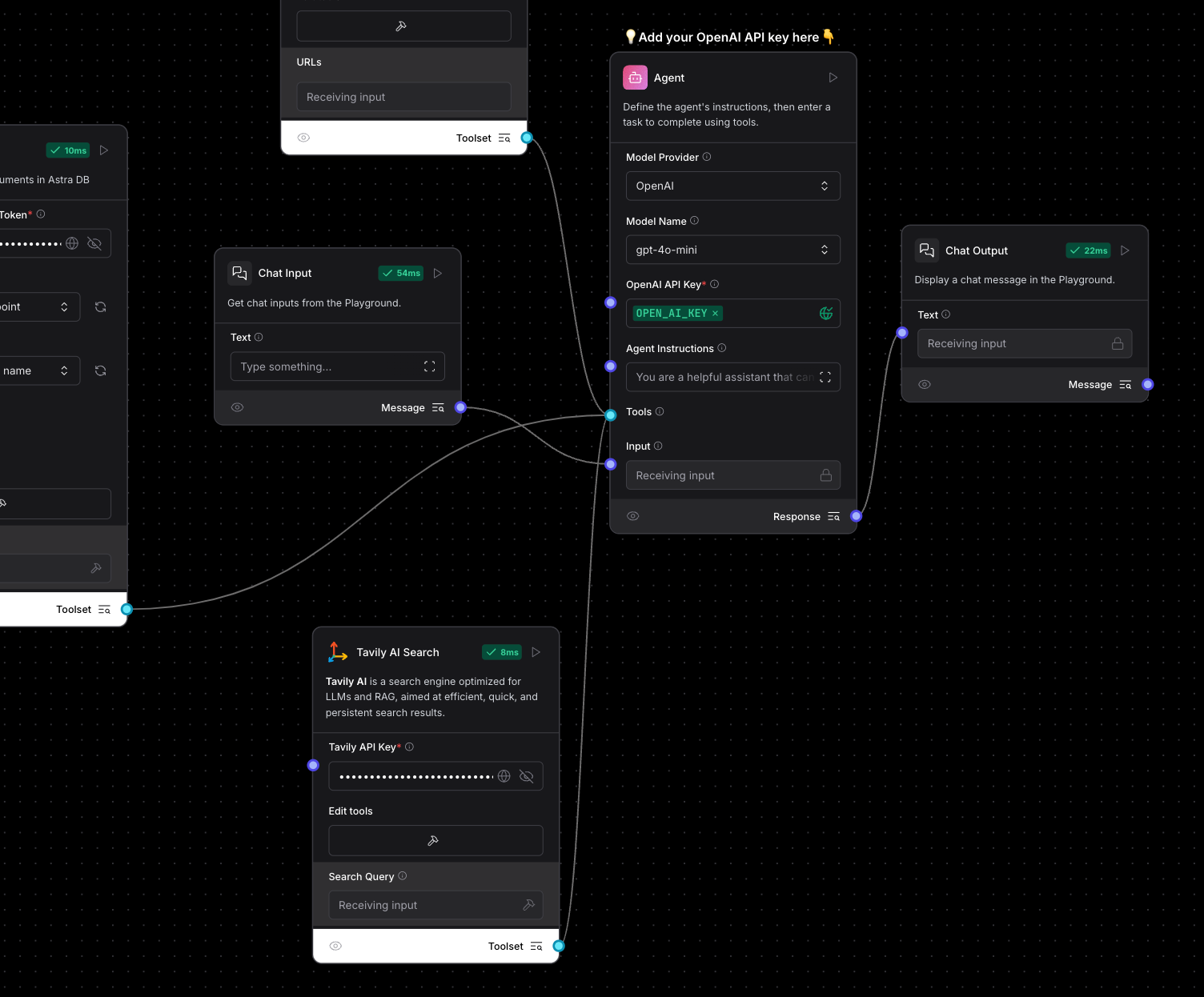
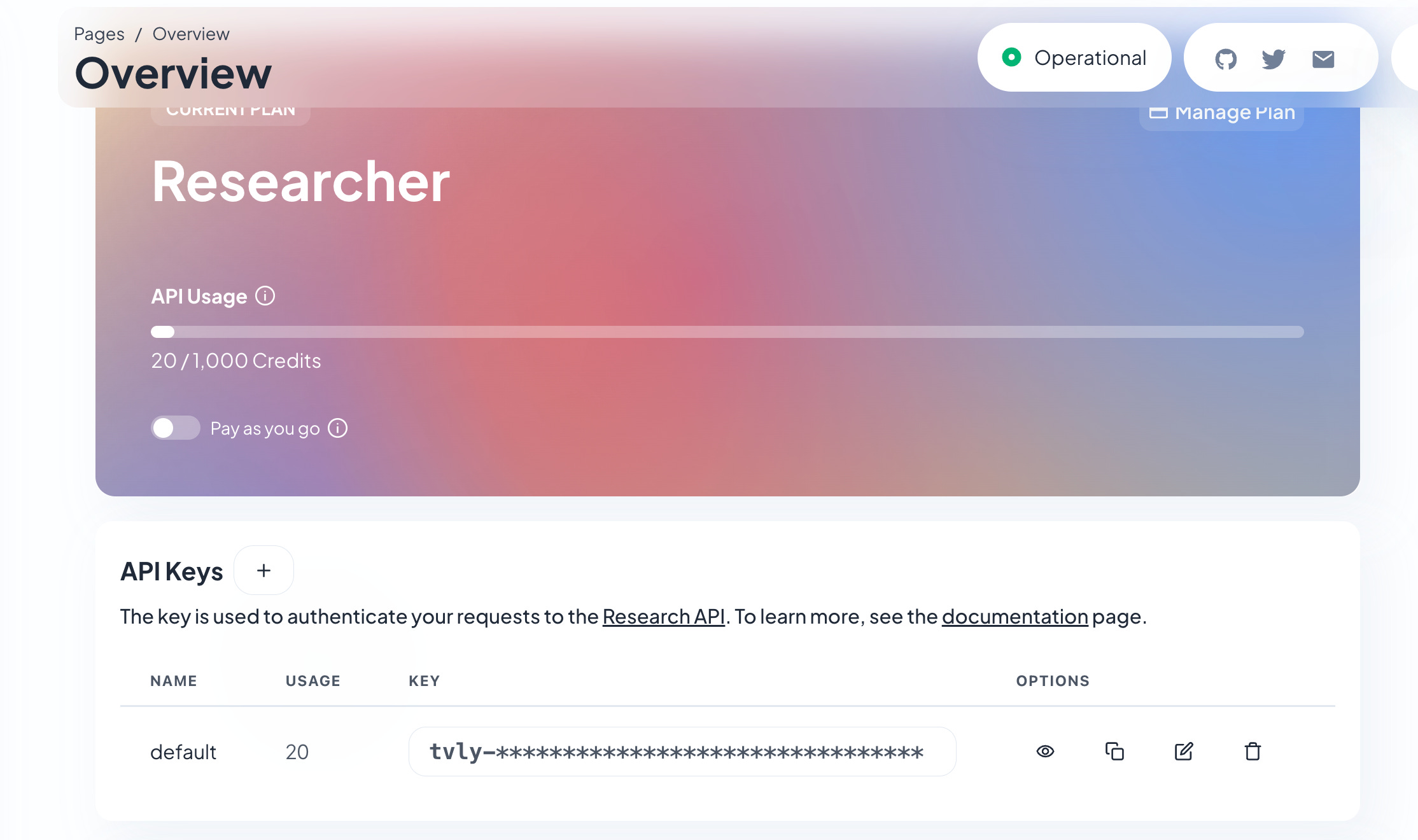
Let’s head over to Tavily website and generate a Key for us.
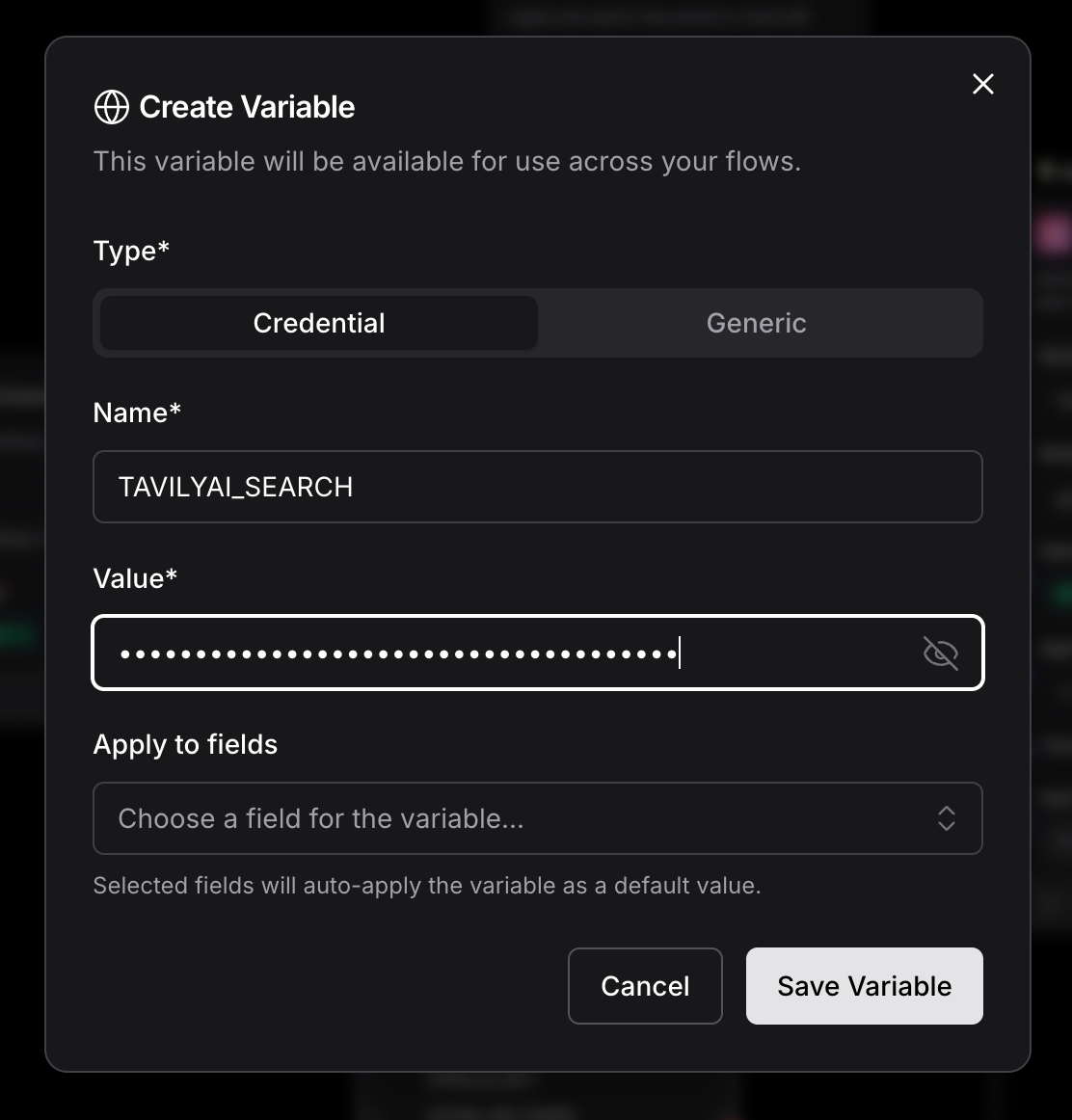
Let’s define the Key as Global Variable within Langflow once again.
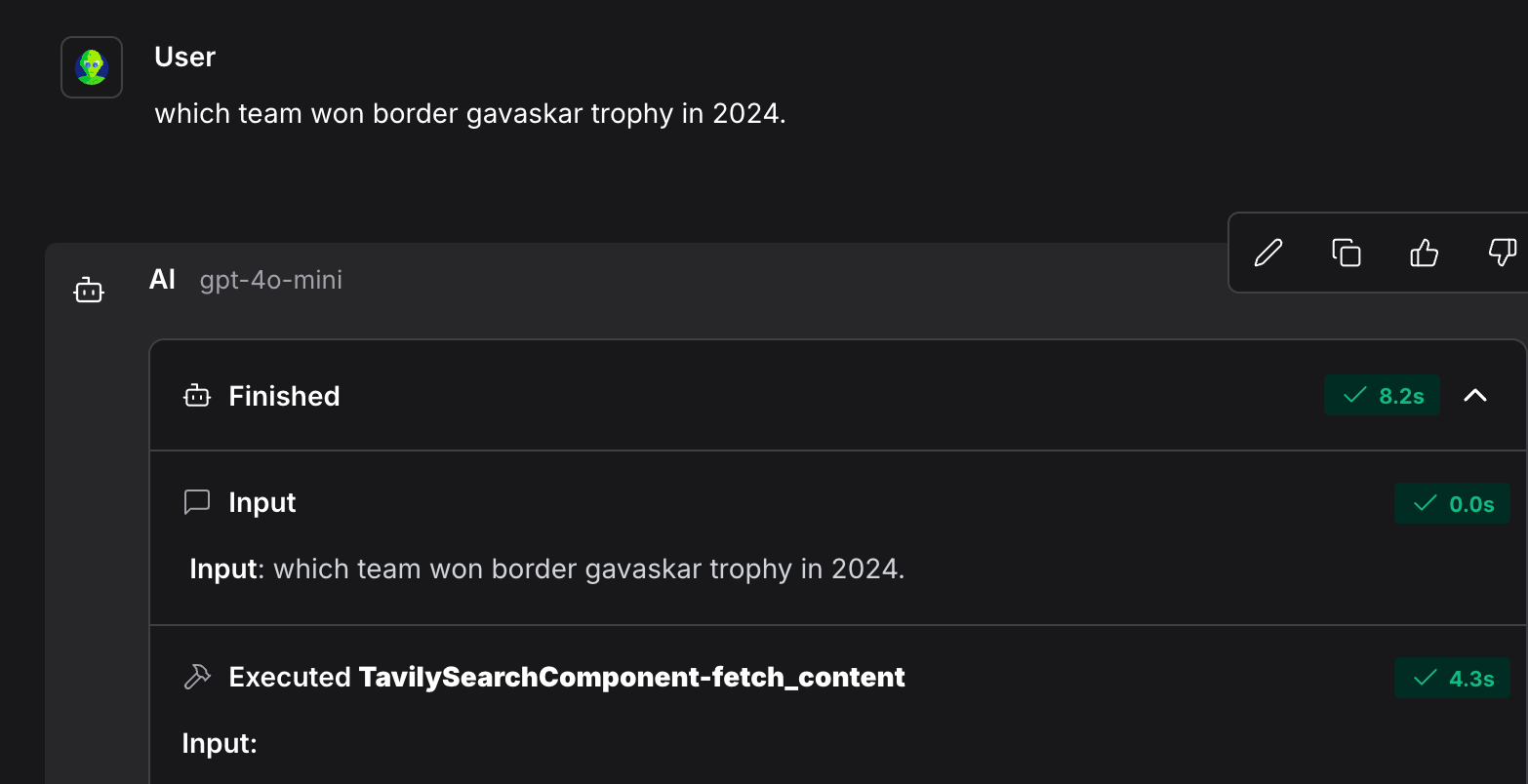
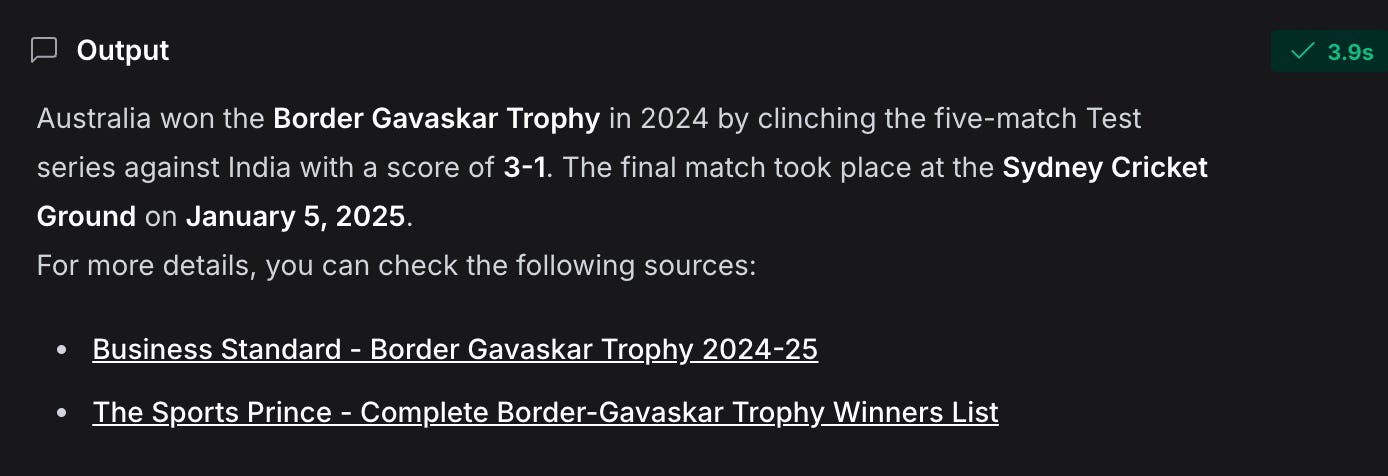
Everything is set up now. Being an avid cricket fan, I decided to ask the model about the results of the Border-Gavaskar Trophy.
And there it is—the AI Agent used the TavilySearchComponent to fetch the answer, delivering it in impressive detail.
This covers the basics of creating a RAG model and building an AI Agent from scratch that interacts with various tools, including the RAG model, to provide relevant information based on chat input.
Note:
You can click on any component within the flows and select the “Code Section” to view the underlying code that powers the rendered output.
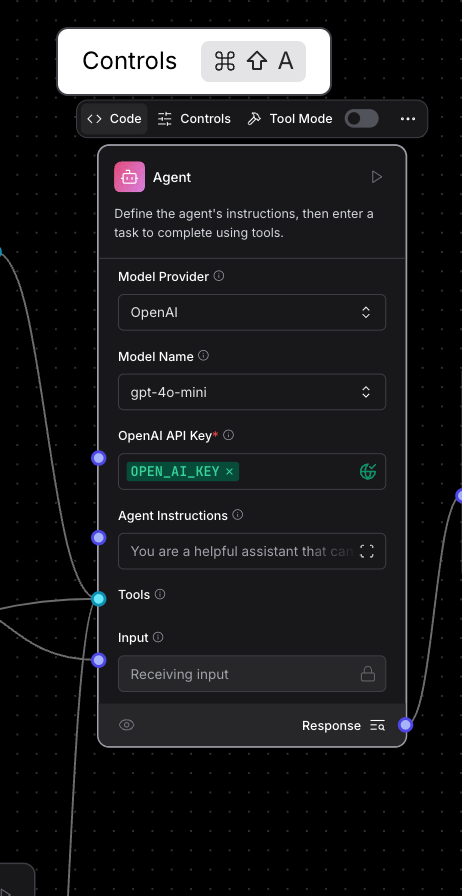
Feel free to change anything and then modify as per your need. A great way to get started.
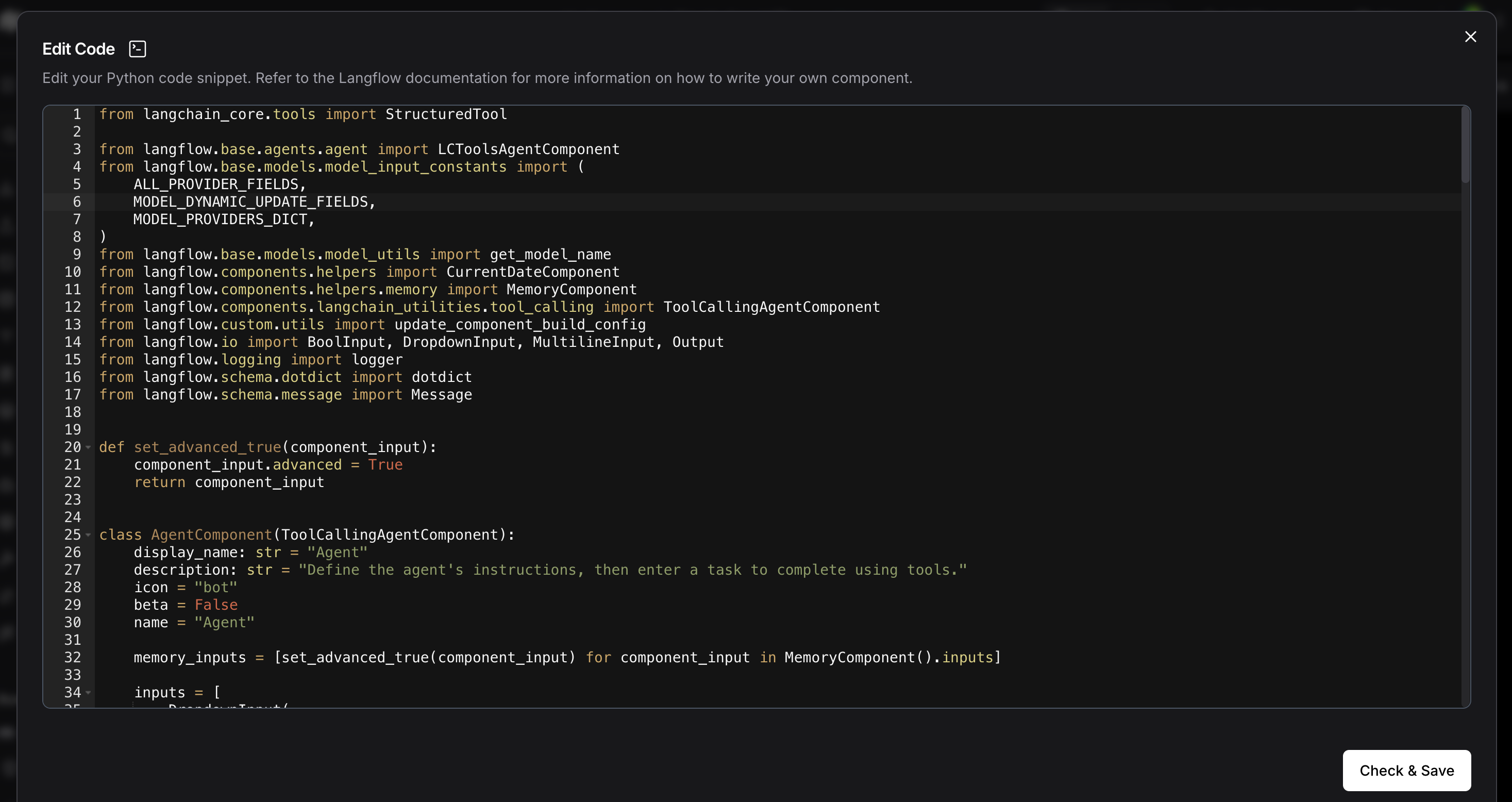
In Langflow, click on the API Section and you can get the Curl request or the API Boilerplate code in multiple language that you can integrate with any app of your choice and can fully utilise the AI Agent using the flow that we just created.
I have copied the curl in Postman and modified the input_value to a sample query and the model responds with the appropriate answer.
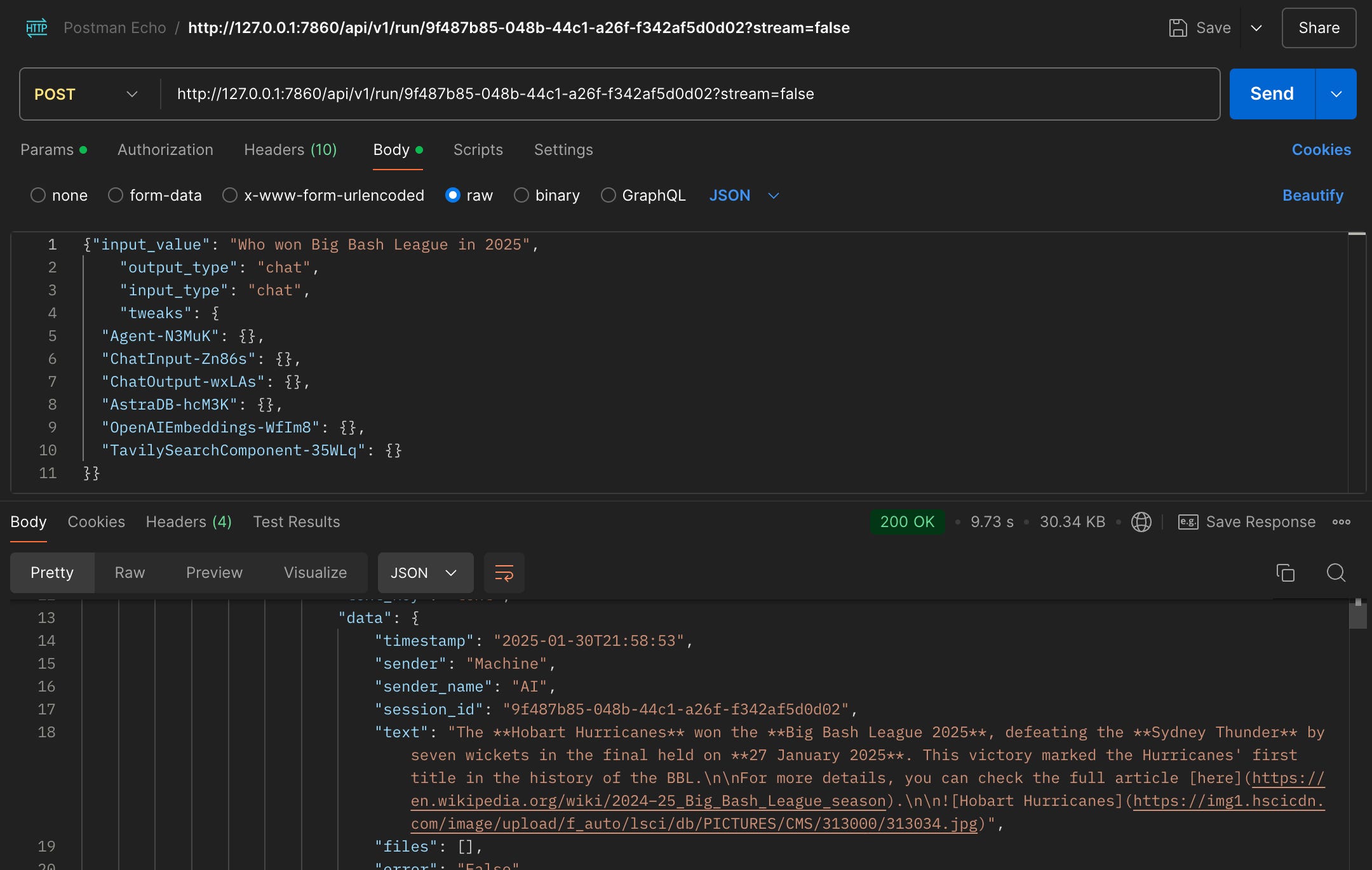
I tested my flows using Postman and found the responses accurate and seamless.
Unlocking Langflow’s Potential
Langflow simplifies the creation of sophisticated AI workflows while abstracting the underlying complexity. You can even view and modify the code for any component or export the flow as API-ready boilerplate in multiple languages.
I surely had fun playing around with Langflow.
I’d love to see your creations! If you encounter challenges, feel free to reach out.